微软语音识别系统达到了5.1%的错误率, 那么语音识别还有哪些难点需要攻破呢?
时间:2017-08-23 来源:互联网 浏览量:
语音到文字的转换是语音研究领域的重要课题,可以说语音识别是众多研究团队和企业正在努力攻克的技术高地,有关识别准确率的竞争和比较从未停止。

自引入神经网络的方法以来,语音识别正确率有了长足的进展,也为苹果 Siri、亚马逊 Echo、科大讯飞语音输入法等等实际产品提供了生长的土壤。去年,微软率先实现语音识别系统5.9%的低错误率,在Switchboard对话语音识别任务中已经达到人类对等的水平。

今年的8月20日,微软语音和对话研究团队负责人黄学东兴奋地公布了他们的最新进展,他们的语音识别系统也达到了同样的5.1%的错误率。这是业界的新的里程碑,也比他们去年的成绩又有显著的提高。
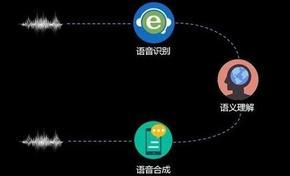
近二十年来,语音识别技术取得显著进步,开始从实验室走向市场。人们预计,未来10年内,语音识别技术将进入工业、家电、通信、汽车电子、医疗、家庭服务、消费电子产品等各个领域。
语音识别还是存在几大难点
一、让语音识别机器能够听懂人的“话”

所谓用户的独立性,就是语音识别软件能够识别有不同嗓音和口音的用户,而无需通过训练软件来使其识别一个特殊用户的声音。目前的许多语音识别软件,是基于标准的发音来进行识别的。而实际上,人们说话千差万别,发音也各不相同,特别对于有口音的语音来说,更是对语音识别软件提出了严峻的挑战。
二、机器掌握自然语言的能力
许多语音识别系统还具有自然的语言能力,这就是软件理解讲话者的能力。这种能力不仅表现在特定的单词上,甚至还表现在短语和完整的句子上。
三、语音识别身份的能力

语音识别还可以发展软件身份验证的能力,即根据用户的嗓音和语言特点,来达到识别用户的能力。这在实际中是一个非常有价值的特点,如可用于人事管理上。
四、鸡尾酒会问题

这是指有多个说话人情况下的语音识别问题,比如鸡尾酒会上很多人讲话。这种情况下人是有可能听清楚你关注的人在说什么的,当然手势、口型、表情以及聊天话题都会提供帮助。这种环境下的语音识别是相当有挑战的。
相关资讯
最新热门游戏
微软资讯推荐
- 1 微软重新定义的学生本值得买吗?文化的差异是个问题
- 2 微软首席执行官:隐私是一项需要被保护的人权
- 3 华为余承东:Win10系统已经OK了,现在可以继续欢呼
- 4Windows 10最新预览版“任务管理器”增加GPU性能追踪
- 5免费升级win10倒计时还有4天,现在不升级将来要多花800块
- 6微软又开始抛弃用户: 仅11款WP手机支持创意者更新(开放和封闭, 微软对于这个问题有自己的理解)
- 7Wintel联盟要掰? 微软展示首款Win 10-ARM笔记本
- 8电脑要卖不出去?戴尔、微软、惠普都急了
- 9微软将在10月份停止对Win10 1511的支持
- 10最强游戏机来了! 微软Xbox One X国行过审 期待不?
