「腾讯 AI Lab副主任俞栋」过去两年基于深度学习的声学模型的进展
时间:2017-09-15 来源:互联网 浏览量:

新智元推荐

1. 引言
过去几年里,自动语音识别(ASR)已经取得了重大的进步 [1-21]。这些进步让 ASR 系统越过了许多真实场景应用所需的门槛,催生出了 Google Now、微软小娜和亚马逊 Alexa 等服务。这些成就中很多都是由深度学习(Deep Learning)技术推动的。
在这篇论文中,我们调查了过去两年的新进展,并重点关注了声学模型。我们讨论了所调查的每一项有趣的研究成果的动机和核心思想。具体而言,第 2 节中,我们阐释了使用深度循环神经网络(RNN)和深度卷积神经网络(CNN)的改进的 DL/HMM(深度学习-隐马尔可夫模型)混合声学模型。比起前馈深层神经网络(DNN),这些混合模型能更好地利用语境信息,并由此得到了新的当前最佳的识别准确度。
第 3 节中,我们描述了仅使用很少或不使用不可学习组件的以端到端方式设计和优化的声学模型。我们首先讨论了直接使用音频波形作为输入特征的模型,其特征表征层是自动学习到的,而不是人工设计的。然后我们描述了联结主义时序分类(Connectionist Temporal Classification, CTC)标准优化的模型,该模型允许序列到序列的直接映射。之后我们分析了构建于注意机制之上的序列到序列翻译模型。
第 4 节中,我们讨论了可以提升稳健性的技术,并重点关注了自适应技术、语音增强和分离技术、稳健训练技术。第 5 节中,我们描述了支持高效解码的声学模型并涵盖了通过教师-学生训练(teacher-student training)与量化实现的跳帧和模型压缩。第 6 节中,我们提出了正待解决的核心问题以及有望解决这些问题的未来方向。
2. 利用可变长度语境信息的声学模型
DL/HMM 混合模型 [1-5] 是第一种在 ASR 上取得成功的深度学习架构,而且仍然是这一行业使用的主导模型。几年前,大多数混合系统都是基于 DNN 的。
但是,由于音素和语速的不同,语境信息的最优长度也可能各不相同。这说明像在 DNN/HMM 混合系统中一样使用固定长度的语境窗口(context window)可能并非利用语音信息的最佳选择。近几年,人们已经提出了一些可以更有效地利用可变长度语境信息的新模型。其中最重要的两个模型使用了深度 RNN 和 CNN。
A. 循环神经网络(RNN)
前馈 DNN 仅会考虑固定长度的帧的滑动窗口中的信息,因此无法利用语音信号中的长距离相关性。而 RNN 可以编码自己内部状态中的序列历史,因此有望基于截止当前帧所观察到的所有语音特征来预测音素。但不幸的是,纯粹的 RNN 难以训练。
为了克服这些问题,研究人员开发了长短期记忆(LSTM)RNN [23]。LSTM-RNN 使用输入门、输出门和遗忘门来控制信息流,使得梯度能在相对更长的时间跨度内稳定地传播。
为了得到更好的建模能力,一种流行的做法是将 LSTM 层堆叠起来 [8]。但带有太多 vanilla LSTM 层的 LSTM-RNN 非常难以训练,而且如果网络太深,还会有梯度消失问题。这个问题可以使用 highway LSTM 或 residual LSTM 解决。
在 highway LSTM [29] 中,相邻层的记忆单元通过门控的直接链路连接在一起,这为信息提供了一种在层之间更直接且不衰减地流动的路径。
residual LSTM [30,31] 在 LSTM 层之间使用了捷径连接(shortcut connection),因此也提供了一种缓解梯度消失问题的方法。
另外还有一种二维时频 LSTM(2-D, time-frequency (TF) LSTM)[35, 36],可以在时间和频率轴上对语音输入进行联合扫描,以对频谱时间扭曲(spectro-temporal warping)建模,然后再将其输出的激活(activation)用作传统的时间 LSTM 的输入。这种时间-频率联合建模能为上层的时间 LSTM 提供更好的规范化的特征。
网格 LSTM(Grid LSTM [38] )是一种将 LSTM 记忆单元排布成多维网格的通用 LSTM,可以被看作是一种将 LSTM 用于时间、频谱和空间计算的统一方法。
尽管双向 LSTM(BLSTM)通过使用过去和未来的语境信息能得到比单向 LSTM 更好的表现,但它们并不适合实时系统,因为这需要在观察到整个话语之后才能进行识别。因为这个原因,延迟受控 BLSTM(LC-BLSTM)[29] 和行卷积 BLSTM(RC-BLSTM)等模型被提了出来,这些模型构建了单向 LSTM 和 BLSTM 之间的桥梁。在这些模型中,前向 LSTM 还是保持原样。但反向 LSTM 会被替代——要么被带有最多 N 帧前瞻量的反向 LSTM(如 LC-BLSTM 的情况)替代,要么被集成了 N 帧前瞻量中的信息的行卷积替代。
B. 卷积神经网络(CNN)
卷积神经网络(CNN)是另一种可以有效利用可变长度的语境信息的模型 [42],其核心是卷积运算(或卷积层)。
时延神经网络(time delay neural network/TDNN)是第一种为 ASR 使用多个 CNN 层的模型。这种模型在时间轴和频率轴上都应用了卷积运算。
继DNN 在 LVCSR 上的成功应用之后,CNN 又在 DL/HMM 混合模型架构下被重新引入。因为该混合模型中的 HMM 已经有很强的处理 ASR 中可变长度话语问题的能力了,所以重新引入 CNN 最初只是为了解决频率轴的多变性 [5,7,44,45]。其目标是提升稳健性,以应对不同说话人之间的声道长度差异。这些早期模型仅使用了一到两个 CNN 层,它们和其它全连接 DNN 层堆叠在一起。
后来,LSTM 等其它 RNN 层也被集成到了该模型中,从而形成了所谓的 CNN-LSTM-DNN (CLDNN) [10] 和 CNN-DNN-LSTM(CDL)架构。
研究者很快认识到处理可变长度的话语不同于利用可变长度的语境信息。TDNN 会沿频率轴和时间轴两者同时进行卷积,因此能够利用可变长度的语境信息。基于此,这种模型又得到了新的关注,但这一次是在 DL/HMM 混合架构之下 [13,47],并且出现了行卷积 [15] 和前馈序列记忆网络(feedforward sequential memory network/FSMN) [16]等变体。
最近以来,主要受图像处理领域的成功的激励,研究者提出和评估了多种用于 ASR 的深度 CNN 架构 [14,17,46,48]。其前提是语谱图可以被看作是带有特定模式的图像,而有经验的人能够从中看出里面说的内容。在深度 CNN 中,每一个更高层都是更低层的一个窗口的非线性变换的加权和,因此可以覆盖更长的语境以及操作更抽象的模式。和有长延迟困扰的 BLSTM 不一样,深度 CNN 的延迟有限,而且如果可以控制计算成本,那就更加适用于实时系统。
为了加速计算,我们可以将整个话语看作是单张输入图像,因此可以复用中间计算结果。还不止这样,如果深度 CNN 的设计能保证每一层的步幅(stride)长到能覆盖整个核(kernel),比如基于逐层语境扩展和注意(layer-wise context expansion and attention/LACE)的 CNN [17]和dilated CNN [46],它仅需更少数量的层就能利用更长范围的信息,并且可以显著降低计算成本。
3. 使用端到端优化的声学模型
在 DNN/HMM 混合模型中,DNN 和 HMM 两个组件通常是分别进行优化的。然而,语音识别是一个序列识别问题。如果模型中的所有组件都联合进行优化,那就很可能得到更好的识别准确度。如果模型可以移除所有人工设计的组件(比如基本特征表征和词典设计),那结果甚至可以更好。
A. 自动学习到的音频特征表征
对语音识别而言,人工设计的对数梅尔滤波器组特征(log Mel-filter-bank feature)是否最优还存在争议。受机器学习社区内端到端处理的启发,研究者们一直在努力 [49-52] 试图用直接学习滤波器替代梅尔滤波器组提取。直接学习滤波器就是使用一个网络来处理原始的语音波形,并且与识别器网络联合训练而得到滤波器。
远场 ASR 领域当前的主导方法仍然是使用传统的波束成形方法来处理来自多个麦克风的波形,然后再将经过波束成形处理过的信号输入给声学模型 [54]。在使用深度学习执行波束成形以及波束成形和识别器网络的联合训练上,都已经有了一些研究工作 [55-58]。
B. 联结主义时序分类(CTC)
语音识别任务是一种序列到序列的翻译任务,即将输入波形映射到最终的词序列或中间的音素序列。声学模型真正应该关心的是输出的词或音素序列,而不是在传统的交叉熵(CE)训练中优化的一帧一帧的标注。为了应用这种观点并将语音输入帧映射成输出标签序列,联结主义时序分类(CTC)方法被引入了进来 [9,60,61]。为了解决语音识别任务中输出标签数量少于输入语音帧数量的问题,CTC 引入了一种特殊的空白标签,并且允许标签重复,从而迫使输出和输入序列的长度相同。
CTC 的一个迷人特点是我们可以选择大于音素的输出单元,比如音节和词。这说明输入特征可以使用大于 10ms 的采样率构建。CTC 提供了一种以端到端的方式优化声学模型的途径。在 deep speech [15, 63] 和 EESEN [64,65] 研究中,研究者探索了用端到端的语音识别系统直接预测字符而非音素,从而也就不再需要 [9,60,61] 中使用的词典和决策树了。
确定用于 CTC 预测的基本输出单元是一个设计难题。其中,预先确定的固定分解不一定是最优的。[68] 中提出了 gramCTC,可以自动学习最适合目标序列的分解。但是,所有这些研究都不能说是完全端到端的系统,因为它们使用了语言模型和解码器。
因为 ASR 的目标是根据语音波形生成词序列,所以词单元(word unit)是网络建模的最自然的输出单元。[18] 中表明通过使用 10 万个词作为输出目标并且使用 12.5 万小时数据训练该模型,发现使用词单元的 CTC 系统能够超越使用音素单元的 CTC 系统。
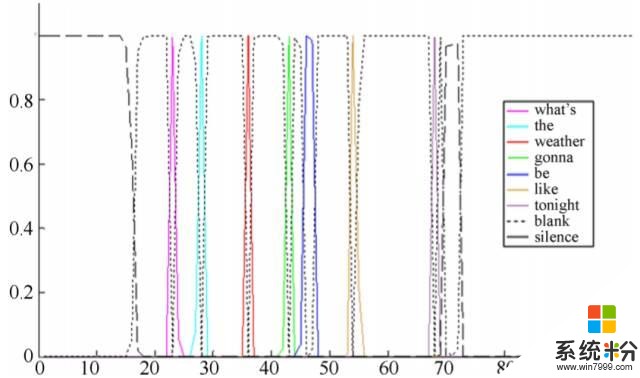
图 1:词 CTC 的一个示例
受 CTC 研究的启发,最近有研究者提出了无 lattice 最大互信息(lattice-free maximum mutual information/LFMMI),可以无需从交叉熵网络进行初始化,就能从头开始训练深度网络。
总体来说,从 DNN 到 LSTM(时间建模)再到 CTC(端到端建模),声学模型存在一个清晰的主要发展路径。尽管使用音素作为建模单元时,LFMMI 等一些建模技术可以得到与 CTC 类似的表现,但它们可能并不非常符合端到端建模的趋势,因为这些模型需要专家知识来设计,也需要语言模型和词典等组件才能工作。
C. 基于注意的序列到序列翻译模型
基于注意(attention)的序列到序列模型是另一种端到端模型 [71,72]。它源自机器学习领域内一种成功的模型 [73,74],即使用注意解码器(attention decoder)对编码器-解码器框架 [75] 进行了扩展。
这种基于注意的模型并没有像 CTC 那样假设帧是独立的,这也是注意模型的一大优势。这种基于注意的模型的训练难度甚至比 CTC 模型还大。
基于注意的模型也有不能单调地从左到右对齐和收敛缓慢的缺点。在 [76] 中,通过将 CTC 目标函数用作辅助成本函数,注意训练和 CTC 训练以一种多任务学习的方式结合到了一起。这样一种训练策略极大地改善了基于注意的模型的收敛,并且缓解了对齐问题。
4. 声学模型稳健性
当测试集和训练集匹配时,尤其是当两者处在相当接近的对话条件下时,当前最佳的系统能够得到很出色的识别准确度。但是,在有更多噪声(包括音乐或干扰性说话人)或带有很强口音 [78,79] 等不匹配或复杂环境中时,系统的表现将大打折扣。这一问题的解决方案包括自适应、语音增强和稳健建模。
A. 声学模型自适应
鉴于自适应数据有限,所以与说话人相关(SD)模型和与说话人无关(SI)模型的差距应该不大。参考文献 [82] 为训练标准加入了Kullback-Leibler divergence(KLD)正则化,防止自适应的模型偏离 SI 模型太远。这种 KLD 自适应标准已被证明可以非常有效地处理自适应数据有限的情况。
与其调整自适应标准,大多数研究关注的是如何使用非常少量的参数来表征说话人的特征。奇异值分解(SVD)瓶颈自适应 [84] 是解决方案之一,这种方法可以通过使用 SVD 重构的结构得到占用资源低的 SD 模型 [85]。
k×k 的 SD 矩阵通常是对角主导矩阵,这一观察启发研究者提出了低秩加对角(low-rank plus diagonal/LRPD)分解,这种方法可以将 k×k 的 SD 矩阵分解成一个对角矩阵加上两个低秩矩阵的乘积。
另一种旨在寻找变换的低维子空间的方法是子空间方法(subspace method),这种方法仅需少量参数就能指定每种变换。这一类别内的一种流行方法是使用辅助特征,比如 i-vector [89,90]、说话人代码 [91] 和噪声估计 [92],这些特征会与标准的声学特征串接在一起。
其它子空间方法还包括聚类自适应训练(CAT)[96,97] 和 factorized hidden layer(FHL),其中的变换会被局限在说话人子空间中。
CAT 风格的方法有一个问题,就是它的基(base)是满秩矩阵,这需要非常大量的的训练数据。因此,CAT 中的基的数量通常局限在少量几个 [96,97]。使用 FHL [98,99] 是一种解决方案,这种方法将基限制为秩一矩阵。通过这样的方式,能够减少每个基所需的训练数据,从而能在训练数据固定的条件下增加基的数量。
B. 语音增强和分离
众所周知,当语音中掺杂了很强的噪声或干扰语音时,当前的 ASR 系统的表现会变得很差 [105,106]。尽管人类听者也会受到糟糕的音频信号的影响,但表现水平的下降程度比 ASR 系统要明显小很多。
在单声道语音增强和分离任务中,会假设只有线性混合的单麦克风信号已知,其目标是恢复音频源中的每一个音频流。语音的增强和分离通常在时频域进行。
研究者近来已经为语音的增强和分离开发了很多深度学习技术。这些技术的核心是将增强和分离问题转化成一个监督学习问题。更具体来说,就是给定配对的(通常是人工)混合语音和声源流,针对每个时频区间(time-frequency bin),优化深度学习模型使其能预测声源是否属于目标类别。
与说话人无关的多说话人语音分离的难度在于标签的模糊性或排列问题。因为在混合信号中,音频源是对称的,所以在监督学习过程中,并不能预先确定的将正确源目标分配给对应输出层。因此,模型将无法很好地训练以分离语音。幸运的是,人们已经提出了几种用于解决标签模糊性问题的技术。
Hershey et al. [111, 112] 提出了一种被称为深度聚类(deep clustering/DPCL)的全新技术。这种模型假设每个时频区间都仅属于一个说话人。在训练过程中,每个时频区间都被映射到了一个嵌入空间。然后对这个嵌入进行优化,使属于同一个说话人的时频区间在这个空间中相距更近,属于不同说话人的则相距更远。在评估过程中,该模型会在嵌入上使用一个聚类算法来生成时频区间的分区。
Yu et al. [20] 和 Kolbak et al. [21] 则提出了一种更简单的技术排列不变训练(permutation invariant training/PIT)来攻克与说话人无关的多说话人语音分离问题。在这种新方法中,源目标被当作一个集合进行处理(即顺序是无关的)。在训练过程中,PIT 首先根据前向结果在句子层面上确定误差最小的输出-目标分配。然后再最小化基于这一分配的误差。这种策略一次性地简单直接地解决了标签排列问题和说话人跟踪问题。PIT 不需要单独的跟踪步骤(因此可用于实时系统)。相反,每个输出层都对应于源的一个流。
对于语音识别,我们可以将每个分离的语音流馈送给 ASR 系统。甚至还能做到更好,基于深度学习的声学模型也许可以和分离组件(通常是 RNN)进行端到端的联合优化。因为分离只是一个中间步骤,Yu et al. [124] 提出直接在 senone 标签上使用 PIT 优化交叉熵标准,而不再需要明确的语音分离步骤。
C. 稳健的训练
深度学习网络的成功是因为可以将大量转录数据用于训练数以百万计的模型参数。但是,当测试数据来自一个新领域时,深度模型的表现仍然会下降。
最近,为了得到对噪声稳健的 ASR,对抗训练 [125] 的概念也得到了探索 [126-128]。这种解决方案是一种完全无监督的域适应方法,不会利用太多关于新域的知识。它的训练是通过在编码器网络的域鉴别器网络之间插入一个梯度反向层(gradient reverse layer/GRL)实现的。
最近,为了不使用转录数据执行自适应,研究者提出了教师/学生学习(teacher/student (T/S) learning)方法 [132]。来自源域的数据由源域模型(教师)处理,以生成对应的后验概率或软标签(soft label)。这些后验概率被用于替代源自转录数据的硬标签(hard label),以使用来自目标域的并行数据训练目标模型(学生)。
5 具有有效解码的声学模型
通过堆叠多层网络训练深度网络有助于改善词错率(WER)。但是,计算成本却是个麻烦,尤其是在实时性具有很高的优先级的行业部署中。降低运行时成本的方法有好几种。
第一种方法是使用奇异值分解(SVD)。SVD 方法是将一个满秩矩阵分解成两个更低秩的矩阵,因此可以在保证再训练之后准确度不下降的同时显著减少深度模型中的参数数量。
第二种方法是采用教师/学生(T/S)学习或知识精炼(knowledge distillation),从而通过最小化小规模 DNN 和标准的大规模 DNN 的输出分布之间的 KLD 来压缩标准的 DNN 模型。
第三种方法是通过大量量化来压缩模型,既可以应用非常低比特的量化,也可以用向量量化。
第四种解决方案是操作模型结构。为了降低计算成本,研究者提出了一种带有投射层的 LSTM(LSTMP),即在 LSTM 层之后增加一个线性投射层 [8]。
最后,可以使用跨帧的相关性来降低评估深度网络分数的频率。对于 DNN 或 CNN 而言,这可以通过使用跳帧(frame-skipping)策略完成,即每隔几帧才计算一次声学分数,并在解码时将该分数复制到没有评估声学分数的帧 [149]。
6 未来方向
这一领域的研究前沿已经从使用近距离麦克风的 ASR 变成了使用远场麦克风的 ASR,这种发展的推动力是用户对无需佩戴或携带近距离麦克风就能与设备进行交互的需求的日益增长。
尽管为近距离场景开发的很多语音识别技术都可以直接用于远场场景,但这些技术在远距离识别场景中的表现不佳。为了最终解决远距离语音识别问题,我们需要优化从音频捕获(如麦克风阵列信号处理)到声学建模和解码的整个流程。
作者简介 | 俞栋博士
腾讯AI Lab副主任及西雅图实验室负责人
俞栋博士是首批将深度学习应用到语音识别领域的研究者,60项专利发明人及开源软件CNTK开发者,曾任职美国微软、并兼浙大、中科大及上海交大等教职。
他有浙大电子工程学士、美国印第安纳大学计算机硕士、中科院自动化所模式识别与智能控制硕士及爱达荷大学计算机博士等学位。
本文经授权转载自腾讯AI实验室
点击阅读原文可查看职位详情,期待你的加入~
