挑战机器阅读理解界的“ImageNet”, 微软亚洲研究院重回榜单第一
时间:2017-09-25 来源:互联网 浏览量:
近日,斯坦福大学NLP小组发推特称,微软提交了最新一次SQuAD的测试成绩,再次夺回得了该数据集测试榜单第一的位置。
自然语音理解长期以来被誉为“人工智能皇冠上的明珠”,让机器学会阅读和理解人类语言一直是研究者和业界关注的对象,今年以来更是受到了极大的追捧,热度不减。
由斯坦福大学李飞飞教授发起的ImagNet,是目前世界上图像识别最大的数据库,试图让冰冷的机器读懂照片背后的故事。而在斯坦福大学自然语言组发起的挑战赛SQuAD,行业内公认的机器阅读理解标准水平测试,也是该领域的顶级赛事,更是被誉为机器阅读理解界的”ImageNet”。
参赛者来自全球学术界和产业界的研究团队,包括微软亚洲研究院、艾伦研究院、IBM、Salesforce、Facebook、谷歌以及卡内基·梅隆大学、斯坦福大学等知名企业研究机构和高校,赛事对自然语言理解领域的学术进步和人才选拔都起到重要作用。
SQuAD比赛规则是怎样?对于机器的阅读理解,如何作答和评判?
SQuAD挑战赛通过众包的方式构建了一个大规模的机器阅读理解数据集(包含10万个问题),就是将一篇几百词左右的短文给人工标注者阅读,让标注人员提出最多5个基于文章内容的问题并提供正确答案;短文原文则来源于500多篇维基百科文章。
参赛者提交的系统模型在阅读完数据集中的一篇短文之后,回答若干个基于文章内容的问题,然后与人工标注的答案进行比对,得出精确匹配(Exact Match)和模糊匹配(F1-score)的结果。得益于SQuAD提供的大规模高质量的训练数据以及层出不穷的模型,该挑战赛的榜单一次又一次刷新。
以下是最新排名,MSRA位居第一:
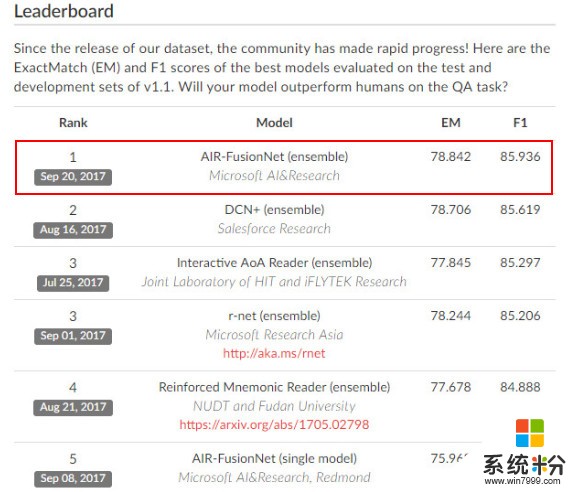
微软亚洲研究院常务副院长、NLP小组组长周明曾表示,从这个数据集成立之初MSRA就开始有所关注,这个数据集的规则是需要不停刷新排名,隔一段时间就要提交最新的测试成绩。MSAR连续多次位居数据集排名第一。
“虽然偶尔有一两天其它团队超过了我们的成绩,但我们也有最新的算法能够很快地进行更新,并取得更好的成绩,对于这一点我们的团队始终十分自信。”机器阅读理解研究的主要负责人、微软亚洲研究院自然语言计算研究组主管研究员韦福如曾这样说。
此外,国内业界代表科大讯飞也在关注并参与该数据集的比赛,7月份科大讯飞与哈工大联合实验室(HFL)提交的系统模型在测试中夺得第一名,同样实力不俗。足以可见自然语言处理领域竞争十分激烈。
自然语言处理领域一直是实现人机交互、人工智能的重要技术基石,机器阅读理解正是这一领域的一个研究焦点。如今异常火热的智能语音助手,最关键的除了“听清”就是“听懂”,语音技术在不断完善,而自然语言理解的进展则相对较为缓慢。万里长征可谓刚刚起步,NLP产业界和学术界均任重道远。
相关资讯
- 科大讯飞力压微软获机器阅读理解SQuAD测试第一
- 科大讯飞机器阅读理解挑战赛力压微软夺冠: 水平相当6岁儿童
- 科学匠人|看微软亚洲研究院如何识人、用人、育人
- 微软发布SynNet:两步打造可迁移学习的机器阅读理解系统
- 微软亚洲研究院资深研究员梅涛:原来视频可以这么玩了! | CCF-GAIR 2017
- 学术盛宴:微软亚洲研究院CVPR 2017论文分享会全情回顾
- 微软亚洲研究院CVPR圆桌: 机器学习火成这样, 如何让计算机视觉“独立”发展?
- 人工智能的三个关键词: 访微软亚洲研究院副院长张益肇
- 微软亚洲研究院郑宇: 为什么柯洁又输了, 专业棋手反而觉得有希望了?
- 微软亚洲研究院张霖涛: AI发展的三个支柱点--数据、算法、系统
最新热门游戏
微软资讯推荐
- 1 微软重新定义的学生本值得买吗?文化的差异是个问题
- 2 微软首席执行官:隐私是一项需要被保护的人权
- 3 华为余承东:Win10系统已经OK了,现在可以继续欢呼
- 4Windows 10最新预览版“任务管理器”增加GPU性能追踪
- 5免费升级win10倒计时还有4天,现在不升级将来要多花800块
- 6微软又开始抛弃用户: 仅11款WP手机支持创意者更新(开放和封闭, 微软对于这个问题有自己的理解)
- 7Wintel联盟要掰? 微软展示首款Win 10-ARM笔记本
- 8电脑要卖不出去?戴尔、微软、惠普都急了
- 9微软将在10月份停止对Win10 1511的支持
- 10最强游戏机来了! 微软Xbox One X国行过审 期待不?
