微软旗下Maluuba推出看图问答数据集, 想让AI看懂图表
时间:2017-10-24 来源:互联网 浏览量:447
科学图表能简洁地概括趋势、速率和比例等有价值的信息,让我们直观地了解概念。而机器对这种结构化视觉信息的理解能帮助我们从大量文献中提取信息。
这不,微软旗下的Maluuba对这事的研究有了新进展。
近日,Maluuba推出了一个用于推理的可视化数据集FigureQA,并将研究相关论文《FigureQA: An Annotated Figure Dataset for Visual Reasoning》发布在ArXiv上。量子位挑其重点编译整理,与大家分享。
数据集简介
在关系推理最新研究的启发下,研究人员推出了FigureQA数据集,其中包含了基于10多张图表的100多万对问答,用于研究机器理解和推理方面的问题。
FigureQA数据集中有五种常见的图表模型,这些图表能显示连续的和分类信息,分别为折线图、点图、垂直柱状图、水平条形图和饼图。而其中的问答对,会涉及到图表中元素一对一和一对多的关系,例如:X是中位数吗?X与Y相交吗?得出正确答案需要对多图表中的要素进行推理。
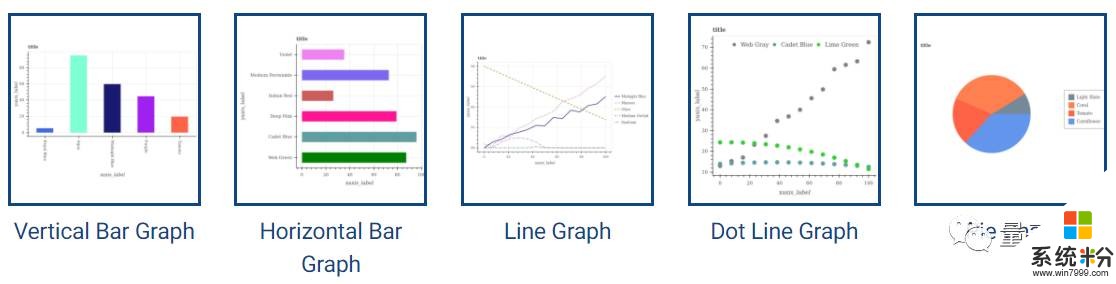
△ 数据集中包含的5种图表类型
数据集中的问题,共有15种类型,涉及到数值大小、最大值、最小值、中值、曲线下面积、平滑度和图像交叉点等信息。

△ FigureQA中包含的15类问题
问答集中问题均基于上述问题,答案统一为“是”或“否”。
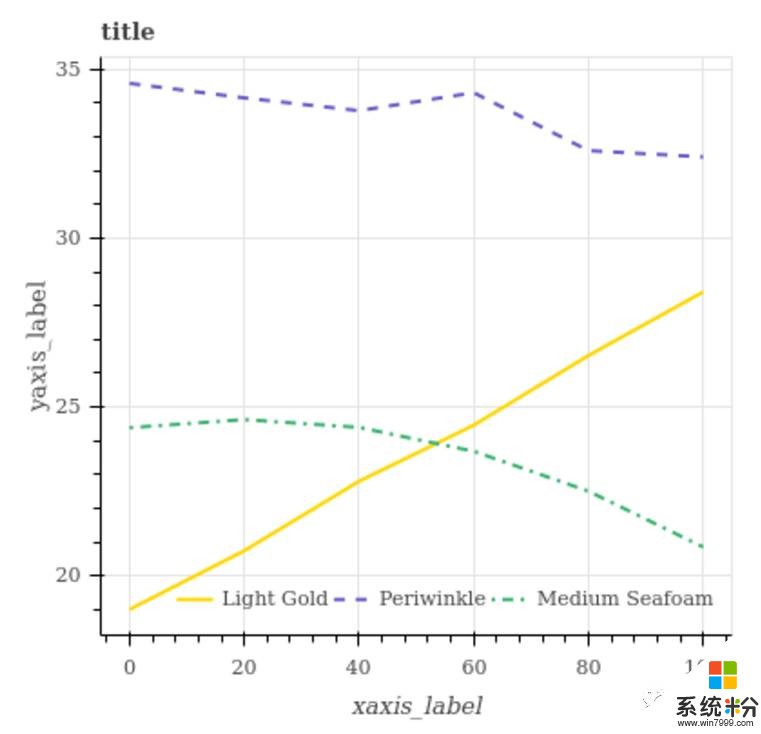
△ 数据集以问答的形式呈现。Q:Medium Seafoam和Light Gold相交吗?A:是。Q:Medium Seafoam是否有最低值?A:否
微软团队在介绍论文中表示:“FigureQA是一个合成的数据集,类似视觉推理相关的CLEVR数据集。虽然数据没有真实环境中那么丰富,但能更大程度控制任务的复杂性,还支持辅助监管信号。此外,通过分析在FigureQA上训练的模型真实数据,还能扩展语料库处理弱项问题。”
制作过程
FigureQA数据集的生成制作分阶段进行。
首先,研究人员根据一组经过仔细调整的约束和启发式设计对数值数据进行采样,让使取样数据显得更自然。随后,研究人员用开源可视化库Bokeh绘制图表中的数据,得到定量数据。
此外,研究人员修改了所有图表的Bokeh后端输出的边界信息:包括数据点、坐标轴、坐标轴标签、标记和图注等信息。他们还提供了底层数值数据和一组边界数据作为每张图表的补充信息。
最后,研究人员平衡了每个问题答案中“是”和“否”的比例,这保证模型不会利用回答频率上的偏差来推断结果,而忽略视觉内容。
测试结果
在论文中,研究人员表示,FigureQA中测试集的准确率还达不到人类水平。接下来,研究人员计划测试在FigureQA上训练的模型在真实科学数据上的表现,并将数据集扩展到人类编写的自然语言问题上。FigureQA“官方”版的数据集可公开使用,是未来研究的基准。
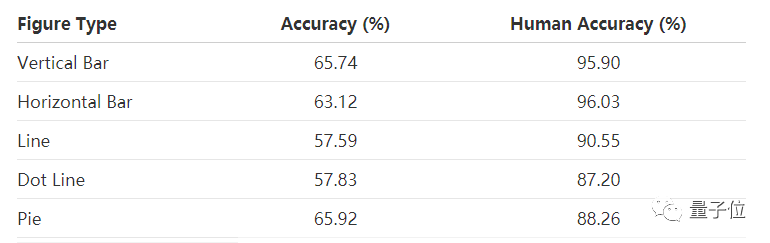
△ 数据集与人类回答15种问题的准确性对比
研究人员还提供了生成脚本,它们配置容易,使用户能调整生成参数生成自己数据。
资料下载
https://datasets.maluuba.com/FigureQA/dl

关于FigureQA的介绍我们可以在ArXiv上一探究竟:
祝你玩得愉快~










