前沿动态 | 微软、阿里用阅读理解证明, 文字的事儿人类已经不如 AI 了
时间:2018-01-18 来源:互联网 浏览量:
人工智能发展到了哪一步?
小卓用一篇阅读理解告诉你答案:
据CNN、CNET、彭博社等多家外媒报道,1月11日,微软和阿里巴巴开发的AI模型在斯坦福阅读测试中首次胜过人类。这是继国际象棋、桥牌等游戏之后,机器再次战胜人类。
机器精准度匹配首次超越人类
SQuAD比赛,是由斯坦福大学发起的机器阅读理解领域顶级赛事,它构建了一个大规模的机器阅读理解数据集(包含10万个问题),文章来源于500多篇维基百科文章。机器在阅读完数据集中的一篇短文之后,需要回答若干个基于文章内容的问题,然后与标准答案进行比对,得出精确匹配(Exact Match)和模糊匹配(F1-score)的结果。
通过这套试题梳理出线索,可看出机器学习模型是否能够在经过大量信息处理后给出问题的确切答案。这些题目所构成的试卷被认为是当前世界检测机器阅读水平的最权威标准之一。
此次测试中,参赛公司让各自的人工智能系统解答斯坦福问答数据集的提问,然后,该数据集评估阅读理解能力,将智能系统与普通人的答案进行比较,并进行排名。结果,微软、阿里巴巴分别以82.650和82.440的精准率打破了世界纪录,并且超越了人类82.304的成绩,刷新了在SQuAD上的排名。
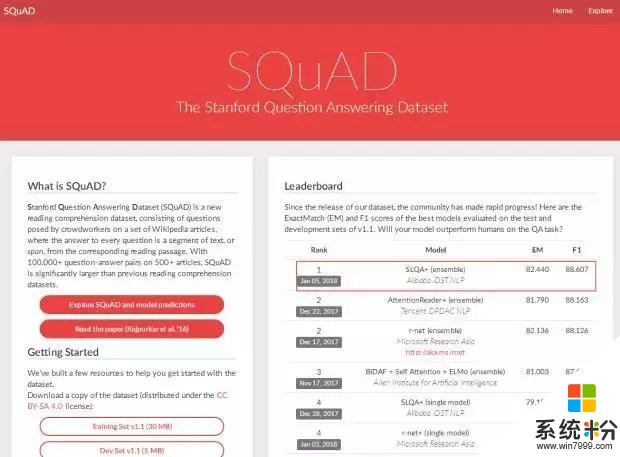
SQuAD的负责人Pranav Rajpurkar在Twitter上表示,“2018年是一个强劲的开始,第一个模型(阿里巴巴iDST团队提交的SLQA +)在精准度匹配上超越人类表现!下一个挑战:模糊匹配,人类仍然领先2.5分!”
理解和分析是机器与人的最大区别
机器阅读理解,虽然看起来仅是让AI进行一场考试,但确实自然语言处理(NPL)技术中,除了语音判断、语义理解之后更大的挑战,即如何让机器理解全文语境。因为阅读理解问题,不止要处理语音和语义,还要关注和理解词汇、语句、篇章结构、思维逻辑、辅助语句和关键句等元素构成的复杂组织网络。
正如做一份阅读理解题,斯坦福阅读理解数据集中会提问:“德国首相出生于哪一年?”紧接着,根据上下文理解,“她的出生地又是哪里?”再比如,“乔治·史密斯是否是美国国籍?”那么这个问题在原文中可寻究的出处是“乔治·史密斯出生于夏威夷,位于美国。”这其中的关键在于,处理阅读理解相关问题,需要的不仅是人工智能的计算能力,更多的是理解和分析能力,而这恰恰是机器与人最大的区别。
值得宽慰的是:从目前来看,机器在复杂语言的理解方面,仍然很难与人类相匹敌。
相关资讯
- 阿里和微软的AI在阅读上击败人类
- 人工智能阅读理解大赛,阿里第一,微软第二,它们都超过了人类
- 人类又一阵地「失守」? 阿里巴巴和微软的 AI 在阅读理解测试中超越人类最高分
- 机器做阅读理解怎样“超越人类”? 微软亚洲研究院为你技术揭秘
- AI阅读理解测试首次击败人类:来自微软和阿里巴巴
- 微软亚洲研究院机器阅读系统在SQuAD挑战赛中率先超越人类水平
- 挑战机器阅读理解界的“ImageNet”, 微软亚洲研究院重回榜单第一
- 云计算诞生四巨头 亚马逊微软阿里云和谷歌四分天下
- 美投资机构Morningstar: 亚马逊、微软、阿里云和谷歌引领全球云计算市场
- 美投资机构: 全球云计算市场诞生四巨头, 亚马逊、微软、阿里云和谷歌引领市场
最新热门游戏
微软资讯推荐
- 1 微软重新定义的学生本值得买吗?文化的差异是个问题
- 2 微软首席执行官:隐私是一项需要被保护的人权
- 3 华为余承东:Win10系统已经OK了,现在可以继续欢呼
- 4Windows 10最新预览版“任务管理器”增加GPU性能追踪
- 5免费升级win10倒计时还有4天,现在不升级将来要多花800块
- 6微软又开始抛弃用户: 仅11款WP手机支持创意者更新(开放和封闭, 微软对于这个问题有自己的理解)
- 7Wintel联盟要掰? 微软展示首款Win 10-ARM笔记本
- 8电脑要卖不出去?戴尔、微软、惠普都急了
- 9微软将在10月份停止对Win10 1511的支持
- 10最强游戏机来了! 微软Xbox One X国行过审 期待不?
