人脸识别居然歧视黑人?微软、IBM被指误差惊人
时间:2018-02-12 来源:互联网 浏览量:
2月9日,纽约时报英文网站发表一篇文章,指出如今非常热门的AI应用人脸识别,针对不同种族的准确率差异巨大。其中,针对黑人女性的错误率高达21%-35%,而针对白人男性的错误率则低于1%。
文章引用了MIT媒体实验室(MIT Media Lab)研究员Joy Buolamwini与来自微软的科学家Timnit Gebru合作的一篇研究论文《性别图谱:商用性别分类技术中的种族准确率差异》(Gender Shades: Intersectional Accuracy Disparitiesin Commercia lGender Classification)中的数据。
论文作者选择了微软、IBM和旷视(Face++)三家的人脸识别API,对它们进行性别判定的人脸识别功能测试。

在一组385张照片中,白人男性的识别误差最高只有1%

在一组271张照片中,肤色较黑的女性识别误差率高达35% 图源:纽约时报,JoyBuolamwini,M.I.T.MediaLab
论文研究使用了自行收集的一组名为Pilot Parliaments Benchmark(PPB)数据集进行测试,里面包含1270张人脸,分别来自三个非洲国家和三个欧洲国家。
在判断照片人物性别方面,以下是论文作者测试后得到的关键发现:
- 所有的分类器在识别男性人脸上的表现要优于女性人脸(8.1%-20.6%的错误差别)
-?所有分类器在肤色较白的人脸上表现优于肤色较深的人脸(11.8%-19.2%的错误差别)
-?所有分类器在肤色较深的女性人脸上表现最差(错误率在20.8%-34.7%之间)
- 微软和IBM的分类器在浅肤色男性人脸上表现最好(错误率分别为0%及0.3%)
- Face++的分类器在肤色较深的男性人脸上表现最好(错误率0.7%)
-?最差的一组与最好的一组差距高达34.4%
需要指出的是,三家人脸识别API都没有很细节地解释自己所使用的分类方法,也没有提及自己所使用的训练数据。
不过,微软在服务中表明“不一定每次都有100%的准确率”;Face++则特别在使用条款中表明对准确性不予保证。
关于可能的原因,时报文章表示,当下的人工智能是数据为王,数据的好坏和多少会影响AI的智能程度。因而,如果用来训练AI模型的数据集中,白人男性的数据多于黑人女性,那么系统对后者的识别能力就会不如前者。
现有的数据集中存在这一现象,比如根据另一项研究的发现,一个被广泛使用的人脸识别数据集中,75%都是男性,同时80%是白人。
旷视回应表示,深色人种数据集比较难获得,所以会差一些;另外,使用RGB摄像头进行人脸识别时,深肤色人的人脸特征比较难找,特别是在暗光条件下,这也是一方面的原因。
IBM回应:论文用的版本太老,新版已改善
针对Buolamwini和Gebru的这一论文发现,2月6日,IBM在自家的IBM Research博客上发表了一篇回应文章。
文章并未否认论文的发现,而是指出,IBM的Watson Visual Recognition服务一直在持续改善,在最新的将于2月23日推出的新版服务中,使用了相比论文中更广泛的数据集,拥有强大的识别能力,相比论文中的错误率有近10倍的下降。
随后文章中表示IBM Research用类似论文中的方法进行了实验,发现如下:
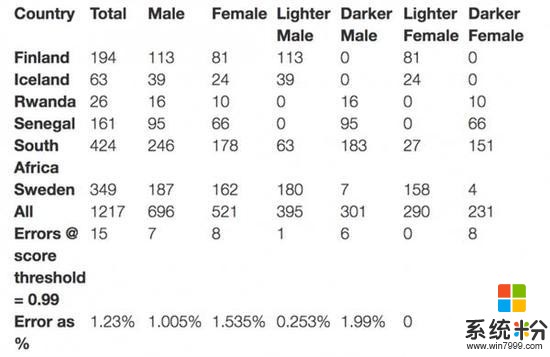
结果显示整体的错误率都很低,虽然肤色较黑的女性的错误率仍然是所有人群中最高的,但相比论文的结果有很大下降。
旷视回应:深肤色人种识别错误率高是普遍现象,在商用产品中会改善
针对这篇论文向旷视寻求回应,对方给予了非常详细的解答。
回应中,旷视首先对论文的研究方法表示认可,但同时指出研究所用的线上API是较旧的版本,在商用的产品中不会出现这类问题;而且,此类问题也是业内普遍存在的,不仅限于测试的这三家。
原因主要有两点,一是深色人种数据集的缺乏,二是深色人种人脸特征较难提取。
以下为回应全文:
我们相信文章(论文)立意不是针对哪一家的技术,基本是不吹不黑的中立态度,而且从文章的测试方法来看还是比较科学的,但是文章中所用的“PPB”(?Pilot Parliaments Benchmark)数据集在GitHub的发布地址已经失效,所以我们目前无法自行检测以验证文章的结论。
在集成到Face++API中的时候,旷视研究院有针对不同人种进行检测、识别等测试。但是就目前国际范围内的研究水平来说,不管是在学界还是产业界,对于肤色人种的识别表现都没有对“肤色较浅(引用文章用词)”人种优秀,从此文的测试结果中也可以看出,微软、IBM和Face++在肤色较深人种识别的表现中(尤其是肤色较深女性)机器的误实率会更高。
一方面从人类基因和人脸识别技术角度来说,皮肤的颜色越深对于基于RGB可见光的人脸识别的难度就越大,因为机器在进行人脸检测、分析和识别的过程中需要对人脸图像进行预处理和特征提取,所以皮肤颜色越深,面部的特征信息就越难提取,尤其是在一些暗光情况下,更加难以检测和区分。
另一方面,人脸识别很大程度上依赖于数据训练,而在整个行业中黑色人种的可训练数据量较少,所以识别的结果在某些程度上不尽人意,所以文章呈现的测试结果是行业普遍存在的现象。文章中只是选取了三家行业代表来进行了测试,如果样本量足够大,那可能还会得出其他的结论。
不过测试结果也显示,Face++对于黑人男性的识别错误率(0.7%)是最低的,且在PPB的南非子测试集中,Face++识别肤色较浅人种的表现是完美无瑕的,这些其实也间接说明Face++的人脸识别能力是处于全球领先的地位。
文章作者提出了一个很好的问题,但文章中测试的API线上版本和我们为用户提供的商业版本无关,用户在业务使用中不会有任何影响。
当然我们也相信行业内都在针对人种识别优化做着各种努力。而就Face++来讲,未来研究院会从几个角度去改善目前的状况,如增加训练数据,针对不同人种进行专门训练,另外是从算法层面优化现在的流程,提升对不同人种的识别性能,此外,旷视也在加大3D感知的研发力度,将三维特征信息融合到应用中弥补二维信息的不足使模型更加鲁棒。
AI真的有歧视吗?
根据时报的报道,论文的作者之一黑人女性Buolamwini做这项研究之前,曾遇到过人脸识别无法识别她的脸,只有在她戴上一张白色面具时才行,因而引发了她开启这项研究。很明显,这项研究试图探讨AI时代是否存在社会不公甚至种族歧视的问题。
种族歧视作为一个非常敏感的话题,许多事情只要有些微沾上点边就会引发强烈反弹。在人脸识别这块,无论是论文作者的研究,还是厂商的实验都明确发现女性深色人种识别误差率更高。但这就能代表AI存有歧视吗?
显然并不是,细究其中的原因,之所以肤色较深女性较难识别,除了有天然人脸特征更难提取之外,还有可供训练的数据集较少的原因。
而从市场的角度来说,IBM和微软的服务在白人男性中表现最好,是因为其市场主要在欧美,而那里白人占多数;旷视的主要市场在东亚和东南亚,因而其在黄种人当中的表现会好很多,这跟歧视没有关系,而是市场导向的技术研发。
话又说回来,这篇论文确实显示,AI的智能性跟训练数据有很大关系,因而在设计AI应用时,我们应该尽量使用广泛且代表性强的数据,照顾到不同的人群;同时要积极对公众解释AI的实现原理。
这件事同时表明,鼓励新技术的发展惠及更多少数族裔是一件需要更多重视的事情,不仅仅是人脸识别,还有语言、文化等各方面。
编辑:齐少恒
相关资讯
- 电脑也要扫一下?Windows将推生物识别解锁
- Windows 10推进掌纹识别:扫一下进系统
- 微软联手小米, 全球首台双 AI 语音助理亮相;京东智能音箱亮相 CES, 支持人脸识别丨AI 掘金晚报
- 人脸识别世界杯 微软百万名人识别竞赛冠军出炉 现实应用指日可待
- 人脸识别哪家强? 苹果FaceID与微软Hello比拼
- 国产鸭梨笔记本上市, 超越微软苹果IBM, 有图有真相, 速看
- 秒iPhone X?华为手机将跟进3D人脸识别
- 拿下微软人脸识别世界杯冠军的中国公司什么背景
- 叶挺孙质疑欧豪太娘,微软人脸识别果然只有他最不像
- 人工智能要闻: 沃尔玛用机器人取代数千岗位, 腾讯开AI加速器, 猎户星空获微软人脸识别有限制类第一名
