全双工语音交互技术四层结构 微软深度展示技术细节
时间:2018-03-29 来源:互联网 浏览量:
在刚刚过去的一周,微软(亚洲)互联网工程院率先公布了新一代语音交互技术:全双工语音交互感官技术(Full-duplex Voice Sense),并宣布该技术已完成在小冰全球产品线中落地。3月28日,微软就全双工语音技术,在北京微软大厦举办了一场媒体闭门分享会,多家主流科技媒体受邀参加,一起交流探讨了人工智能最新基础框架理念的变迁以及代表了人工智能研究前沿的全双工语音交互技术。
微软(亚洲)互联网工程院副院长李笛
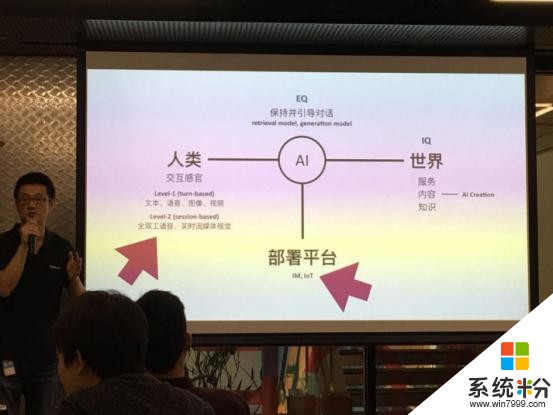
为了让微软小冰与人类真正实现全双工的、不费劲的、流畅自然的语音交互。最新的全双工语音交互技术需要由以下四层结构来支撑实现。即:边听边想、节奏控制器、声音场景的理解、自然语言理解与生成模型。现场微软小冰全球研发负责人、首席架构师周力先生深度剖析揭秘了全双工语音交互技术的四层结构。

微软小冰全球研发负责人、首席架构师周力
一、边听边想。预测模型:现在的微软小冰听到语音后可以预测用户的完整意思,无需再等待用户把一句话说完,再进行识别和回应。持续倾听的同时,便可思考和回应,大大减少了响应的时间,提高了实时修正回答的能力;动态回应:从此人工智能交互不再是被问一句才回答一句的回合制游戏,而是可以更类似人类一样,预估交互对象问题答案,预估思考时间,选择性的完成对交互对象的回答,在交互中同时完成复杂任务,大幅减少用户在交互过程中的等待时间。这对于在Yeelight语音助手等IoT设备上使用微软小冰时的用户体验尤为重要。全双工语音交互技术下的微软小冰,自然交互起来不费劲,等待时间几乎零延迟,这使得微软小冰的用户体验更上一层楼。

二、节奏控制器。节奏协调:包括人工智能自己的协调,与人类交互时的协调,还有和其他人工智能的协调,时机和内容同等重要。其中人工智能可否主动引发新话题,产出新内容,主动打破对话中的沉默时刻是重要特质;不远的将来,基于全双工语音交互技术的人工智能,将拥有和人类一样的非对称对话模式。

微软小冰全球研发负责人、首席架构师周力
三、声音场景的理解。全双工语音交互声音场景包含分类器和环境处理。分类器,目前微软小冰可以完成语音身份识别,比如对男人、女人或儿童的声音进行准确识别,从而提供对应的对话内容,以及语音情绪识别、音乐/歌声识别等;环境处理,目前的微软小冰可以做到识别背景噪声和消除回声,微软小冰既是AI语音助手,同时也是内容的提供者,可以在提供内容的同时完成各项助手功能。比如在分享会上一段令人印象深刻的视频里,小冰正在讲故事,用户反复要求小冰调节音量大小,小冰在不打断跳出讲故事的同时,只是默默在后台执行调节音量的任务;对象判定,目前的微软小冰可以进行语音声纹识别,每个在IoT设备上的微软小冰都可以通过一定时间的“调教”,成功判定数个不同用户和新用户,从而提供不同的个性服务,并且通过识别用户的对话节奏,选择开始或停止响应。

微软小冰全球研发负责人、首席架构师周力
四、自然语言理解与生成模型。目前微软小冰基于此模型可以实现基于对话场景的上下文理解,基于时间、对话内容、用户意图的分类,判断是否主动挂断和拥有更好的容错性与更好的串行语音合成。
微软表示,全双工语音交互技术在微软小冰上的实际应用和产品落地,有望推动整个人工智能行业进入全新时代。在未来5-10年内,获得更广阔的想象空间,为用户的交互体验带来质的飞跃。










