人类又一次被超越!微软亚研自动语法纠错系统达到人类水平
时间:2018-07-05 来源:互联网 浏览量:
选自arXiv,作者:Tao Ge, Furu Wei, Ming Zhou,机器之心编译。

因为 seq2seq 模型在语法纠错上存在缺陷,微软亚洲研究院的自然语言计算团队近日提出了流畅度提升学习和推断机制,用于改善 seq2seq 模型的语法纠错性能。实验表明,改进后的模型取得了当前最佳性能,并首次在两个基准上都超越了人类水平。
用于语法纠错(GEC)的序列到序列(seq2seq)模型(Cho et al., 2014; Sutskever et al., 2014)近年来吸引了越来越多的注意力(Yuan & Briscoe, 2016; Xie et al., 2016; Ji et al., 2017; Schmaltz et al., 2017; Sakaguchi et al., 2017; Chollampatt & Ng, 2018)。但是,大部分用于 GEC 的 seq2seq 模型存在两个缺陷。第一,seq2seq 模型的训练过程中使用的纠错句对有限,如图 1(a)所示。受训练数据的限制,具备数百万参数的模型也可能无法实现良好的泛化。因此,如果一个句子和训练实例有些微的不同,则此类模型通常无法完美地修改句子,如图 1(b)所示。第二,seq2seq 模型通常无法通过单轮 seq2seq 推断完美地修改有很多语法错误的句子,如图 1(b)和图 1(c)所示,因为句子中的一些错误可能使语境变得奇怪,会误导模型修改其他错误。

图 1:(a)纠错句对;(b)如果句子与训练数据有些微的不同,则模型无法完美地修改句子;(c)单轮 seq2seq 推断无法完美地修改句子,但多轮推断可以。
为了解决上述限制,微软研究者提出一种新型流畅度提升学习和推断机制,参见图 2。
对于流畅度提升学习,seq2seq 不仅使用原始纠错句对来训练,还生成流畅度较差的句子(如来自 n-best 输出的句子),将它们与训练数据中的正确句子配对,从而构建新的纠错句对,前提是该句子的流畅度低于正确句子,如图 2(a)所示。研究者将生成的纠错句对称为流畅度提升句对(fluency boost sentence pair),因为目标端句子的流畅度总是会比源句子的流畅度高。训练过程中生成的流畅度提升句对将在后续的训练 epoch 中作为额外的训练实例,使得纠错模型可以在训练过程中看到具有更多语法错误的句子,并据此提升泛化能力。
对于模型推断,流畅度提升推断机制允许模型以多轮推断的方式渐进地修改句子,只要每一次提议的编辑能够提升语句的流畅度,如图 2(b) 所示。对于有多个语法错误的语句,一些错误将优先得到修正。而经修正的部分能让上下文更加清晰,这对模型接下来修改其它错误非常有帮助。此外,由于这种任务的特殊性,我们可以重复编辑输出的预测。微软进一步提出了一种使用两个 seq2seq 模型的往返纠错方法,其解码顺序是从左到右和从右到左的 seq2seq 模型。又因为从左到右和从右到左的解码器使用不同的上下文信息解码序列,所以它们对于特定的错误类型有独特的优势。往返纠错可以充分利用它们的优势并互补,这可以显著提升召回率。
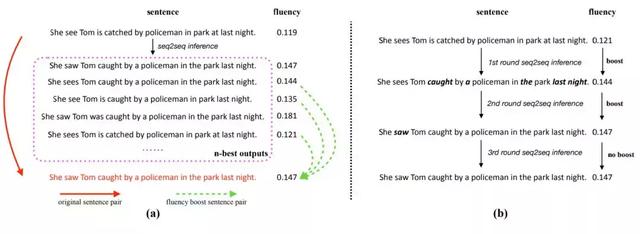
图 2:流畅度提升学习和推断机制:(a)给出一个训练实例(即纠错句对),流畅度提升学习机制在训练过程中从 seq2seq 的 n-best 输出中构建多个流畅度提升句对。流畅度提升句对将在后续的训练 epoch 中用作训练实例,帮助扩展训练集,帮助模型学习;(b)流畅度提升推断机制允许纠错模型通过多轮 seq2seq 推断渐进式地修改句子,只要句子的流畅度一直能够提升。
结合流畅度提升学习和推断与卷积 seq2seq 模型,微软亚洲研究院取得了当前最佳的结果,这使其成为首个在两个基准上都达到人类水平的 GEC 系统。
论文:REACHING HUMAN-LEVEL PERFORMANCE IN AUTOMATIC GRAMMATICAL ERROR CORRECTION: AN EMPIRICAL STUDY

论文地址:https://arxiv.org/pdf/1807.01270.pdf
摘要:神经序列到序列(seq2seq)方法被证明在语法纠错(GEC)中有很成功的表现。基于 seq2seq 框架,我们提出了一种新的流畅度提升学习和推断机制。流畅度提升学习可以在训练期间生成多个纠错句对,允许纠错模型学习利用更多的实例提升句子的流畅度,同时流畅度提升推断允许模型通过多个推断步骤渐进地修改句子。结合流畅度提升学习和推断与卷积 seq2seq 模型,我们的方法取得了当前最佳的结果:分别在 CoNLL-2014 标注数据集上得到 75.02 的 F0.5 分数,在 JFLEG 测试集上得到 62.42 的 GLEU 分数,这使其成为首个在两个基准数据集上都达到人类水平(CoNLL72.58,JFLEG62.37)的 GEC 系统。
2 背景:神经语法纠错
典型的神经 GEC 方法使用带有注意力的编码器-解码器框架将原始句子编辑成语法正确的句子,如图 1(a)所示。给出一个原始句子
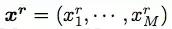
及其纠错后的句子
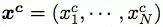
,其中
和
分别是句子 x^r 和 x^c 的第 M 和第 N 个单词,则纠错 seq2seq 模型通过最大似然估计(MLE)从纠错句对中学习概率映射 P(x^c |x^r ),进而学习模型参数 Θ_crt 以最大化以下公式:
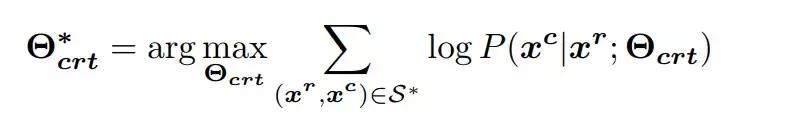
其中 S* 表示纠错句对集。
对于模型推断,通过束搜索输出句子选择
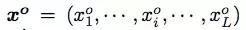
,这一过程需要最大化下列公式:
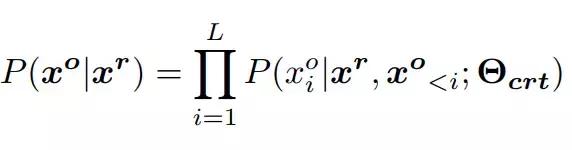
3 流畅度提升学习
用于 GEC 的传统 seq2seq 模型仅通过原始纠错句对学习模型参数。然而,这样的纠错句对的可获得性仍然不足。因此,很多神经 GEC 模型的泛化性能不够好。
幸运的是,神经 GEC 和神经机器翻译(NMT)不同。神经 GEC 的目标是在不改变原始语义的前提下提升句子的流畅度;因此,任何满足这个条件(流畅度提升条件)的句子对都可以作为训练实例。
在这项研究中,研究者将 f(x) 定义为句子 x 的流畅度分数。
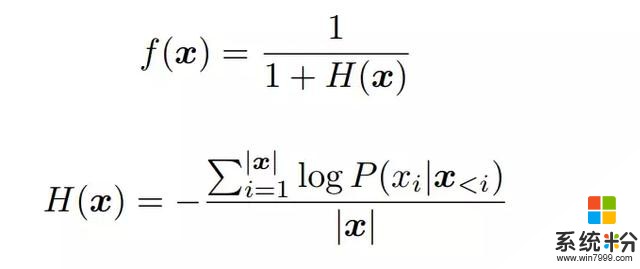
其中,P(x_i | x_<i)是给定上下文 x_<i 下 x_i 的概率,由语言模型计算得到,|x| 是句子 x 的长度。H(x) 是句子 x 的交叉熵,范围为 [0, +∞)。因此 f(x) 的范围为 (0, 1]。
流畅度提升学习的核心思想是生成流畅度提升的句对,其在训练期间满足流畅度提升条件,如图 2(a)所示,因此这些句子对可以进一步帮助模型学习。
在这一部分中,研究者展示了三种流畅度提升策略:反向提升(back-boost)、自提升(self-boost)和双向提升(dual-boost),它们以不同的方式生成流畅度提升句子对,如图 3 所示。
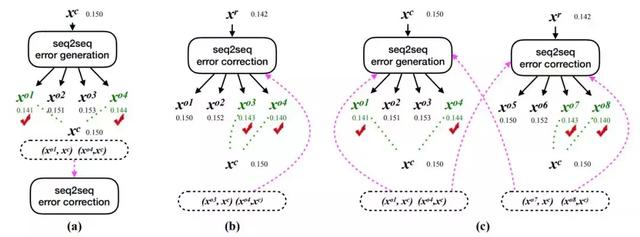
图 3:三种流畅度提升学习策略:(a)反向提升,(b)自提升,(c)双向提升。它们都能生成流畅度提升句对(虚线框中的句对),帮助训练过程中的的模型学习。图中的数字是对应句子的流畅度分数。
4 流畅度提升推断
4.1 多轮纠错
正如在第一节中讨论的,一些具有多个语法错误的语句通常不能通过一般的 Seq2Seq 推断(单轮推断)得到完美的修正。幸运的是,神经 GEC 与 NMT 不同,它的源语言与目标语言相同。这一特征允许我们通过多轮模型推断多次编辑语句,也就产生了流畅度提升推断过程。如图 2(b) 所示,流畅度提升推断允许通过多轮 Seq2Seq 推断渐进式地编辑语句,只要每一次提议的编辑能够提升语句的流畅度。具体来说,纠错 Seq2Seq 模型首先将原语句 x^r 作为输入,并输出假设 x^o1。然后流畅度提升推断将采用 x^o1 作为输入以生成下一个输出 x^o2,而不是将 x^o1 直接作为最终的预测。除非 x^ot 不再能提升 x^ot-1 的流畅度,否则这一过程就不会终止。
4.2 往返纠错
基于多轮纠错的思路,研究者进而提出了一个进阶流畅度提升推断方法:往返纠错。该方法不使用 4.1 中介绍的 seq2seq 模型渐进性地修改句子,而是通过一个从右到左和一个从左到右的 seq2seq 模型依次修改句子,如图 4 所示。

图 4:往返纠错:某些类型的错误(例如,冠词错误)由从右到左的 seq2seq 模型会更容易纠错,而某些错误(例如主谓一致)由从左到右的 seq2seq 模型更容易纠错。往返纠错使得二者互补,相对于单个模型能纠正更多的语法错误。
5 实验
表 2 展示了 GEC 系统在 CoNLL 和 JFLEG 数据集上的结果。由于使用了更大规模的训练数据,因此即使是基础卷积 seq2seq 模型也超越了多数之前的 GEC 系统。流畅度提升学习进一步提升了基础卷积 seq2seq 模型的性能。
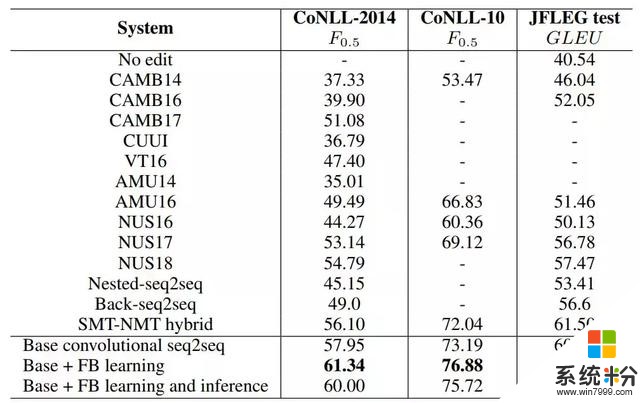
表 2:GEC 系统在 CoNLL 和 JFLEG 数据集上的结果对比。
如表 3 所示,流畅度提升学习提升了基础卷积 seq2seq 模型所有层面的表现(精度、召回率、F0.5 和 GLEU),表明流畅度提升学习确实有助于用于 GEC 的 seq2seq 模型的训练。
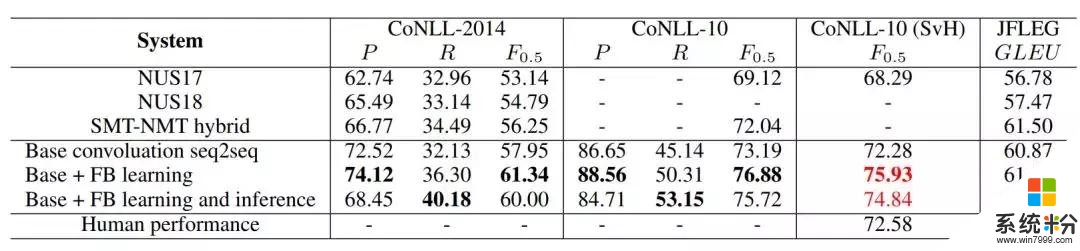
表 3:性能最佳的 GEC 系统在 CoNLL 和 JFLEG 数据集上的评估结果分析。红色字体的结果超越了人类水平。
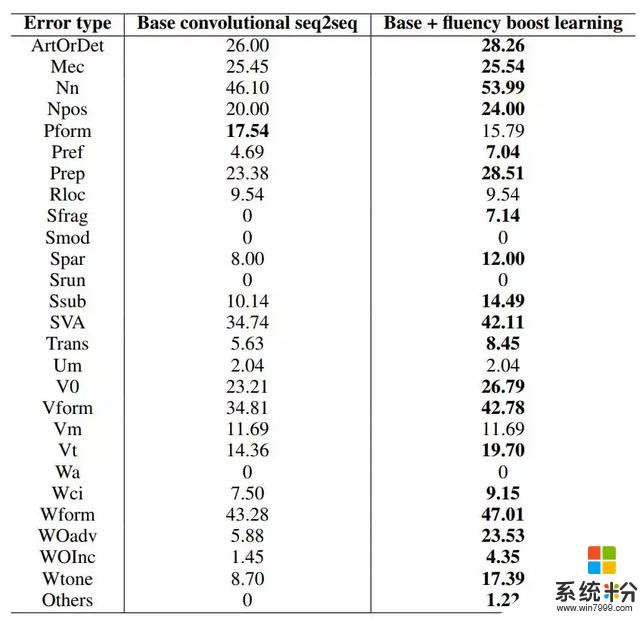
表 4:有/没有流畅度提升学习的卷积 seq2seq 模型在 CoNLL-2014 数据集的每个错误类型上的召回率对比。
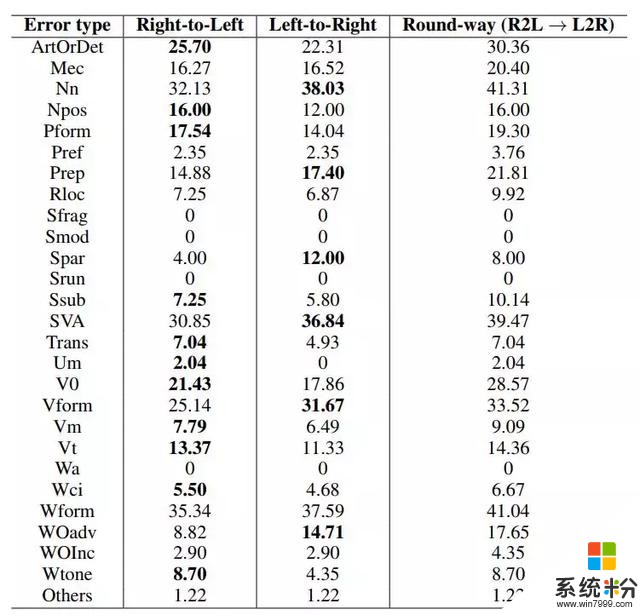
表 5:从左到右和从右到左的 seq2seq 模型对 CoNLL-2014 中每种错误类型的召回率
相关资讯
- 自动驾驶1月29日汇总——微软推开源自动驾驶仿真平台 AirSim教程
- 人类又一阵地「失守」? 阿里巴巴和微软的 AI 在阅读理解测试中超越人类最高分
- 感谢阿里巴巴和微软, 人工智能现在可以在阅读上击败人类了
- 人类再次被AI打败! 阿里巴巴和微软AI在斯坦福阅读测试中击败了人类
- 微软将为Xbox推出成就系统的升级加强版生涯系统
- 微软小冰懂感情有情商 已与人类进行超300亿次对话
- 微软Facebook联手发布AI生态系统, 推出开放神经网络交换格式
- 第五代微软小冰发布 与小米IoT开放平台进行合作
- 微软AI产品小冰更新: 能主动联系人类, 会用她来做帮人的事
- 微软发布第五代小冰, 可以主动给人类打电话
