微软小冰的星辰大海:会对话,唱歌,比喻,还有“人类”想象...
时间:2019-11-24 来源:互联网 浏览量:
11月24日消息 11月21日,微软小冰团队在北京微软大厦举办了Research Workshop活动,科学家团队带来了小冰2019年度最新科研进展及其应用,及对业内技术研发趋势的展望。被邀请参加,在这个微软大厦中的会议厅中,笔者再一次感受到了小冰产品背后的技术原理和对人工智能独特理解的高追求目标。

报道,微软小冰在核心对话引擎方面,经过了经过检索模型、生成模型、共感模型的历次技术迭代,2017年就推出了全双工语音交互感官的上线和产品落地,目前正在发展的面向未来的多模态交互感官,融合了全双工语音交互、实时视觉与核心对话引擎的全新交互感官。小冰也能实现用户与人工智能同时边听边说边看的交互体验。
点对了科技树,微软小冰变得越来越像一个人了。
微软小冰首席科学家宋睿华介绍称,第七代微软小冰已成为全球最大的跨领域人工智能系统之一,产品形态涵盖了社交对话机器人、智能语音助理、人工智能内容创作和生产平台等。在全球多个国家,微软小冰单一品牌已覆盖6.6亿在线用户、4.5亿台第三方智能设备和9亿内容观众,在交互场景拓宽的情况下,微软小冰与用户的单次平均对话轮数(CPS)达到了23轮。

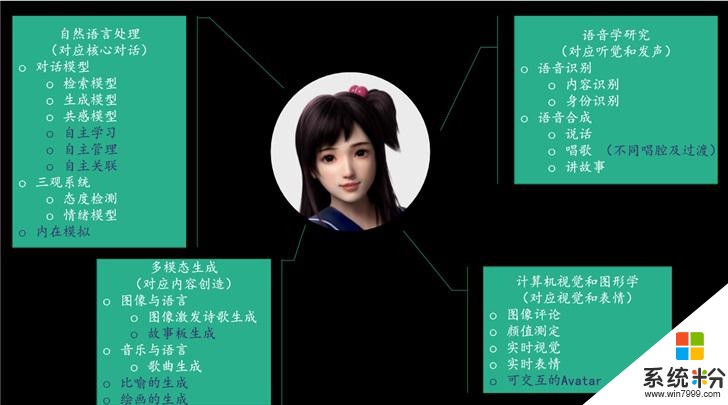
实际上,微软小冰2019年度研究进展活动更像是小冰的科学家们对外公布的一场学术报告会,向等介绍了小冰背后的研发情况,包括NLP自然语言处理、听觉语音学研究、计算机视觉和图形学,还有多模态生成技术等等。

▲微软小冰首席NLP科学家 武威(左)、微软小冰首席语音科学家 栾剑(中)、微软小冰首席科学家 宋睿华(右)
微软小冰在创新方面获得了一定成绩,了解到,小冰团队已经在AAAI、IJCAI、ACL、KDD、ACM MM、WSDM、EMNLP、WSDM等上发表了48篇论文;申请了72项专利,包括全双工、Avatar Framework和多模态方面的领先强大专利;2019年亮点包括发布3篇ACL,1篇IJCAI,4篇EMNLP,1篇InterSpeech,1篇ACM MM长论文,赢得了CLSW 2019杰出论文奖《“Love is as Complex as Math”: Metaphor Generation System for Social Chatbot》,意思是“爱就像数学一样复杂”:社交聊天机器人的隐喻生成系统。
微软小冰的对话研究

微软小冰的基础就是对话,在自然语言处理方面,微软小冰首席NLP科学家武威带来了《Towards a Self-Complete Chatbot》(朝向自我完备的对话机器人)的演讲,其认为一个能够自我完备的对话机器人应该拥有以下能力。也就是说小冰在对话语句上要能够补充所缺乏信息的能力。

能力一,学习——能够从人类的对话中学习怎样去说话。机器人之间可以互相学习,就像人类之间一样。
在检索模型方面,从最简单的LSTM模型到最近的预训练的模型,质量得到非常大的飞跃。而背后代表这个模型从单轮做到多轮,从浅层次表示、匹配到深层次、宽度表示和匹配的发展进程。
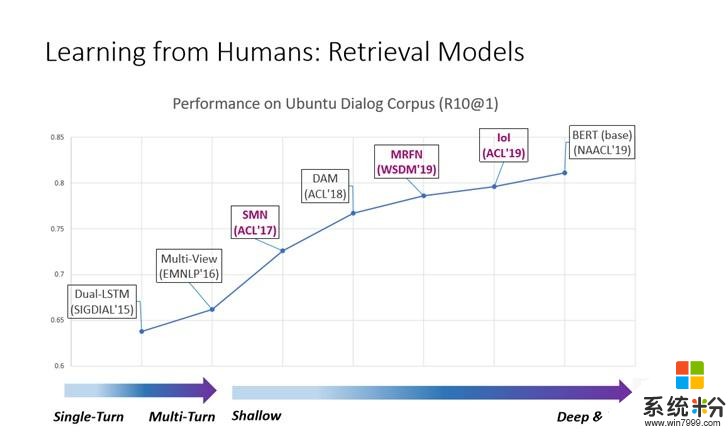
在基础架构方面,可以把用户的输入和回复候选都表示成向量,通过计算向量的相似度来度量这个侯选是不是一个合适的回复。将输入和回复侯选在每一个词上都进行交互,然后得到一个充分的交互矩阵,然后再把交互的信息从这个矩阵中通过神经网络抽取出来,变成一个匹配的程度。
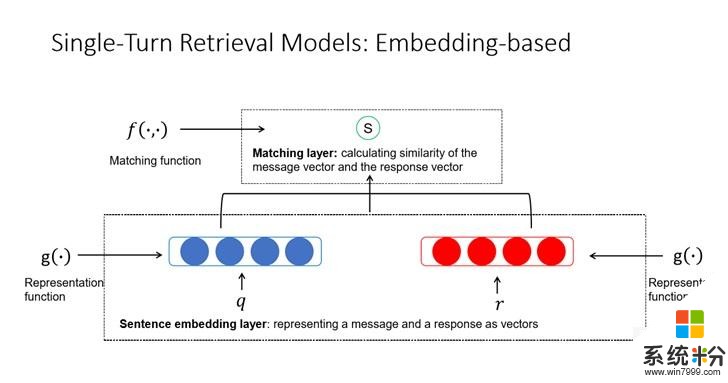
多轮对话交互从单轮对话延伸出来,把一句话表示变成多句话表示,额外把多句的表示糅合成上下文的表示,然后再进行匹配。还可以做细腻度的交互,比如让上下文中的对话与回复候选进行交互,然后再把这些交互信息通过一个神经网络整合起来,变成最后的上下文和回复侯选的匹配程度。
在生成模型方面,逐步做到引入外部知识,从单一模态的回复到可以兼容各种各样的,包括声音、视觉、语言这种模态的生成。通过小冰提出的外部无监督训练话题模型,产生一些话题语料,然后在生成模型中通过话题注意力机制,去遴选话题语料,最后再在解码的过程中单独做出一个话题的生成概率,让话题能够更容易出现在回复中。多轮对话中可通过一种无监督方式,对对话上下文进行补全,然后进行回复。
模型之间也可以互相学习,两个检索模型在训练过程中互为师生,互相交流。在每一次迭代的时候,一个模型都把它从数据中学到的知识传达给另外一个模型,同时又从另外一个模型中接触到它的知识,然后这两个模型互相学习,最终希望能够得到共同的进步。
能力二,自主管理——对话单轮表达。把控整个的对话流程。
在自主管理中,微软小冰对表示,一个有趣的应用是第六代小冰发布的共感模型,包含了回复生成模型、策略决定模型。
共感模型把微软小冰从原来基于上下文直接产生回复的模式,变成了从上下文到决策,然后再根据这个决策来决定我说什么的模式。

其中的策略就是表达意图,可以是话题,也可以是情感等等,当然也可以是意图、话题、情感组合,通过策略组合,可以产生非常多样的、复杂的对话流程。微软通过引入meta-word的概念,代表了属性组合。然后通过变换属性值就可以生成各种各样的回复。
能力三,连结——对话机器人连结散落在世界上的多模态知识。
连结牵扯到多模态交互,输入可以是对话、语音、文本知识、多媒体,输出也可以是对话、语音、多媒体,这其中很重要的问题是机器人如何能够把多模态的知识连结在一起,进行消化、吸收,最终把它有机的组合起来,变成自己的一个输出。
以上是对话机器人这些年来,甚至可能是未来一段时间整个的研究与发展。而微软小冰再加上横线发展,包括从检索模型(重用人类已有话语),到生成模型(合成回复),再到共感模式(自主把握对话流程)。纵线和横线交错发展成对话机器人发展的绚烂画卷。
获知,与其他模型不同的是,微软小冰的共感模型会根据上下文把控对话的流程,不仅要知道上下文是什么,还要根据重要性进行对话的组合,怎样引导对话,来达到有组织有目标的交流,这一般是有很高情商的人类才能做到的。
微软小冰唱歌的研究

网友可能也好奇,小冰为什么要做唱歌呢?微软小冰首席语音科学家栾剑 做出了相关解答。
从前小冰在2015年提出语音聊天功能,声音非常生动活泼,符合小冰个性,后来逐步增加了儿化音、中英文混杂朗读、讲儿童故事、各种情感表现,发现在语音合成领域的一些大方面内容已解决。微软小冰希望寻找更有挑战的课题来做,唱歌就选做了目标,主要有三个目标:
第一,唱歌的门槛比说话高。
第二,情感表达上更加丰富激烈一些。
第三,它是一个很重要的娱乐形式。

但唱歌和说话有什么不同呢?唱歌的很多技术是从语音合成沿袭过来的,据分析它有三大要素:
第一,发音,唱歌吐字发音一定要清晰,和说话一样。
第二,节拍,是通过一种节奏的变化来表现艺术的形式,像我们普通的说唱,比如“一人我饮酒醉”说唱的形式,可能没有其它的旋律,主要就是靠节拍的组合来表达。
第三,旋律,每个字的音高会不太一样,如果音高唱错、跑调,这首歌肯定就没法听了。
所以,这三大要素构成了唱歌最基本的元素,当然还可以叠加很多的技巧,比如颤音、气音之类的。
而机器学习唱歌有两种方式:一种是通过模仿人声去学习,第二种就是通过曲谱方式,通过简谱或者五线谱,配上歌词。简谱涵盖了三大要素,既有歌词,歌词会有发音元素,也会有节拍和音高。前者是简单且广泛的形式,但机器在判断读音时会有误差,后一种反而是便捷且干净的输入。
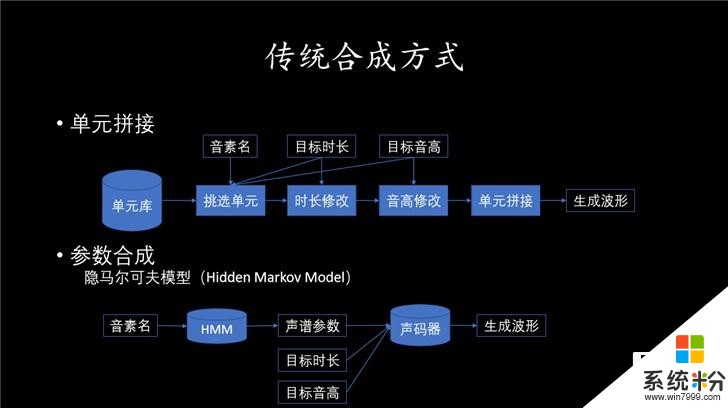
接下来就是唱歌的合成演绎了。可以通过单元拼接的方式,基本思想是建立一个单元库,包括声母和韵母等,通过录制不同字母的发音(不同长度、不同音高)采集,最终加上信号处理方法修改,完美匹配效果,将这些单元串接起来,拼接得到最后的音频。这个方法虽然简单,也可保留采集最佳音质,但单独发音和连续发音区别还是很大,生成歌曲不太自然。
获知,在语音行业里大家熟悉使用的是隐马尔可夫模型,把所有录音数据提取出声学参数,里面可能包括能量谱、时长、音高,然后去建一个模型,要合成的时候,就根据想要的发音到模型里面预测,预测出声学参数,然后通过声学参数、声码器把音频的波形重构出来,方法灵活。不过其中最大的关键点是声码器,参数还原声音过程中,就会有音质的损失。
但微软小冰基于发展需求,一开始就选择了第二种方法,使用模型从乐谱里面采集出三大要素,分别对声谱参数、节奏序列、音高轨迹用三个模型分别建模,采用DNN神经网络,将预测参数通过声码器生成波形。在最新模型里,复杂结构已经用到了卷积神经网络、attentions、其他的残差连接之类技术,使用多个模块,使得三个参数同时建模变成可能,这样生成的波形在自然度和流畅度会得到明显的提升。

在唱歌清唱方面,是严重缺乏数据,绝大部分的数据是混杂的、伴奏的音轨。微软小冰团队在进一步研究如何在伴奏音频中把人声的音高提取更好的模型,从而丰富小冰演唱的风格。
微软小冰学会“比喻”
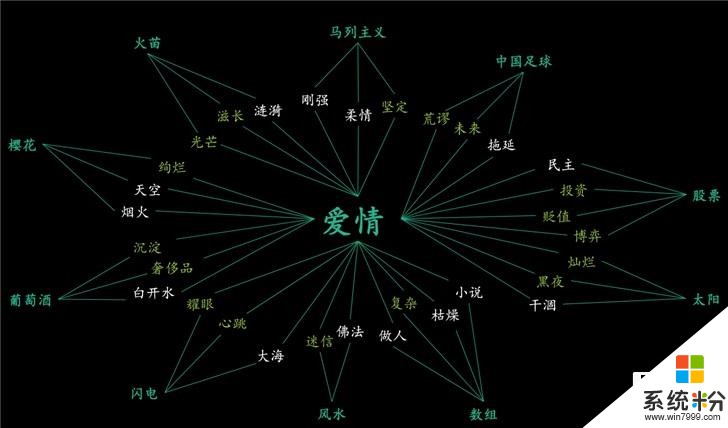
小冰已经学会了写诗、画画、唱歌等操作,那么小冰是否可以创造比喻呢?对于人类而言,比喻是一种生动表达,用于解释抽象的、难以理解的概念。微软小冰首席科学家宋睿华对表示,比喻重要的是能不能找到一种适合小冰的通用规则。

输入是本体,而喻体的输出是解释。本体一般是抽象的,比如说爱情,而喻体是具体的。而这两个概念之间的联系通过用Word Embedding来表达它,将其变成一个向量,经过降维之后,投影在这个二维的空间上。通过自然语言形态的连接词将其结合起来,组成一个比喻。连接词可以在Bing搜索找到句子,并经过NLP分析之后确定关联的相关性。
微软通过三个方面技术了评价:
第一,评判比喻句是否通顺。
第二,评判比喻是否恰当。
第三,评判比喻是否新颖。
最终小冰可以生成类似“孤独像是空无一人的车站,幸福像是可爱的毛毛虫”这样的比喻句,看起来符合常理和认知。

研究发现,小冰的比喻句比陈述句更能吸引人。如果你把它拆成两轮的方式,先卖一个关子,然后再去解释,人们会更喜欢一些。
微软小冰像人类一样想象
微软小冰未来能否像人类一样思考和想象呢?在现场了解到,微软小冰的团队已经开始了相关研究。微软小冰首席科学家宋睿华通过举了一个例子引入了跨模态理解的部分。就是当机器识别到文字和图片后,还能够像人类一样可以启用情绪等感官,让人工智能的反应和回馈更像是人类。

“北极熊爱吃海豹肉,而且爱吃新鲜的”。当人类看到这句话的时候,一开始你会识别出来一些词汇,比如北极熊、海豹,可能你脑海中也会闪现出类似于北极熊的图片或者是可爱的海豹。这些机器也能做到,但是他不能理解北极熊吃海豹可能会流口水。
另外人类在解读这段文字的时候,会自然进行思考理解,“北极熊悄然接近猎物,有时候会用爪子接近自己的鼻子,”因为鼻子是黑色的,这样一来它就会变得更不易察觉,很明显北极熊是在掩盖自己的鼻子。这些文字之外的信息对机器理解来说是非常困难的。
微软团队表示,他们一直想让小冰更像人类,更好的理解对话、更好的理解语言,让小冰能否在语言背后找到一些常识性的内容,即暗含的意思。
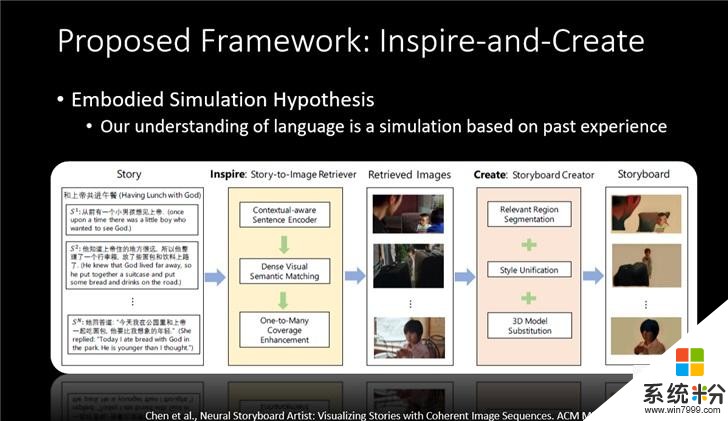
在微软小冰团队的研究中,将这个问题定义成一个故事,它可能由N句话组成,看能不能生成M个图片来对应这N句话,就好像你的脑海中听到了这个故事之后产生的场景一样。然后根据受模拟体验假说,让小冰生成和调用以往的记忆,当新的图像和文字出现后,进行一些模拟场景的匹配或者替换,是的场景更加一致。
如果一句话的信息很多,通过one to many算法检索和插入更多的图片,通过模型和算法逐步完善,去表达出一个更接近人类的故事。

“我们其实想让小冰更像人,你会发现除了工作,听音乐是你很大的一个享受。我觉得人跟动物的不同在于有一定的自主性,人工智能创造体现了一种自主性,包括作曲、写诗、画画,我们做算法的人也不知道最后会产生什么样的结果,你在那一瞬间就会有一个错觉,觉得她有意识,这是非常好的一个点。”宋睿华表示。
相关资讯
最新热门游戏
微软资讯推荐
- 1 微软重新定义的学生本值得买吗?文化的差异是个问题
- 2 微软首席执行官:隐私是一项需要被保护的人权
- 3 华为余承东:Win10系统已经OK了,现在可以继续欢呼
- 4Windows 10最新预览版“任务管理器”增加GPU性能追踪
- 5免费升级win10倒计时还有4天,现在不升级将来要多花800块
- 6微软又开始抛弃用户: 仅11款WP手机支持创意者更新(开放和封闭, 微软对于这个问题有自己的理解)
- 7Wintel联盟要掰? 微软展示首款Win 10-ARM笔记本
- 8电脑要卖不出去?戴尔、微软、惠普都急了
- 9微软将在10月份停止对Win10 1511的支持
- 10最强游戏机来了! 微软Xbox One X国行过审 期待不?
