伯克利与微软联合发布:任意网络结构下的最优GPU通信库Blink
时间:2019-11-25 来源:互联网 浏览量:
作者:Guanhua Wang, Shivaram Venkataraman, Amar Phanishayee 等

论文链接:https://arxiv.org/abs/1910.04940
背景介绍
随着机器学习模型,和数据量的不断增长,模型训练逐渐由单机训练,转变为分布式的多机训练。在分布式深度学习中,数据并行是最为常用的模型训练方式。然而数据并行的模型训练过程中,需要频繁的做数据聚合/模型同步。参与运算的 GPU 数量越多,其对应的数据聚合的开销也会越大。当下单个 GPU 的算力不断增加,GPU 间的数据聚合成成了新的分布式机器学习的瓶颈。
各大公司也发现了数据聚合这个重大瓶颈,因此在软硬件上都提出了自己的解决方案。硬件层面上,GPU 厂商 Nvidia 发布了 GPU 之间直接相连的高速通信通道 NVLink,以及多 GPU 之间的路由器 NVSwitch。软件层面上,各大公司都相继发布了自己的 GPU 通信库(例如:Nvidia 的 NCCL,Baidu 的 Ring-AllReduce),或者针对 GPU 通信进行优化的分布式机器学习平台(最流行的 Uber 的 Horovod)。
然而,这些软件层面上的通信库或者机器学习平台,并没有充分利用所有的,同构和异构的网络通信线路。因此,由 UC Berkeley,Microsoft Research 以及 University of Wisconsin-Madison 组成的研究团队发布,能够充分利用所有同构及异构的网络传输线路,从而实现最优 GPU 间数据聚合的 Blink 项目。
文章简介
当下流行的分布式机器学习平台(Horovod)或 GPU 间数据聚合的通信库(NCCL),其最大问题在于无法很好的解决网络异构性。网络异构性主要表现为如下三点:
1. 同构的 GPU 间链接线路,例如 NVLink,用于不同型号的 GPU 的对应 NVLink 的版本和带宽不同,其组成的网络的拓扑结构也不相同。具体区别如图一所示。
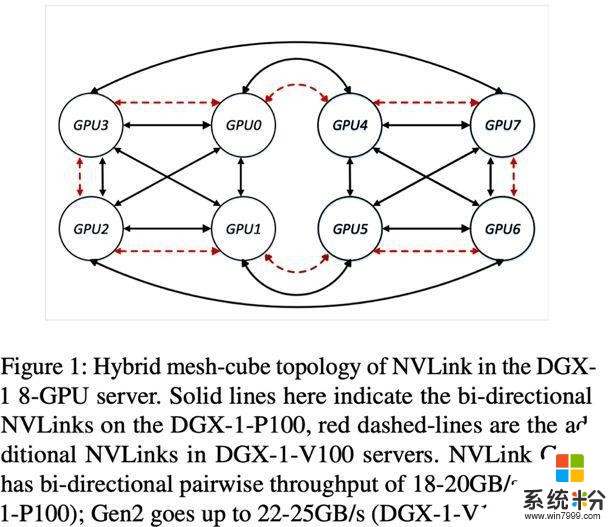
在一个 8 卡的 DGX-1 机器上:如果 GPU 是 P100,其对应的 NVLink 是第一代,带宽为 18-20GB/s,其拓扑结构如图 1 黑线所示。如果 DGX-1 用的 GPU 是 V100,其 NVLink 通信线路为第二代,带宽为 22-25GB/s。于此同时,相比 P100 的 DGX-1,V100 的 DGX-1 的网络拓扑结构也不同,其在 P100 的基础上,新增了一圈红色虚线的 NVLink 线路。
2. 当下主流的 GPU 间数据聚合,使用的是构建环状(Ring)通信通道,其无法很好的利用异构的通信线路。原因很简单,如果用异构的线路构建一个环状网络,整个环的最大带宽被这个环状通道中带宽最小的一段线路所限制。例如用 PCIe 和 NVLink 一起构建一个环状的网络传输通道,则整个环状通道的吞吐率会被 PCIe 的带宽限制,因为 PCIe 的带宽(8-12GB/s)远小于 NVLink(18-25GB/s)。
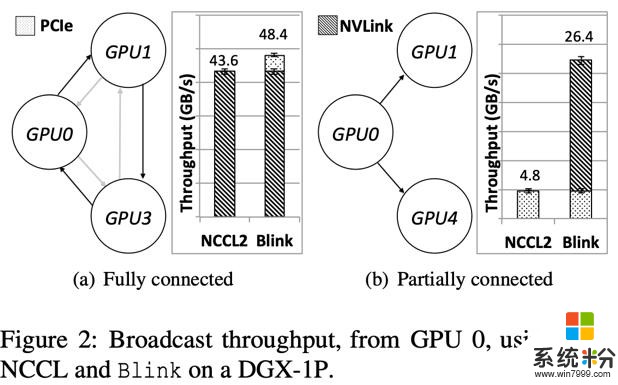
因此,如图 2(a)所示(这里的 GPU 的 ID 可以直接映射在图 1 上),当 GPU 间存在能够建立环状网络的 NVLink 线路时,NCCL/Horovod 就直接放弃 PCIe 这种异构线路,只用 NVLink 构成环状网络进行 GPU 间数据聚合。
3. 在多租户的云计算环境下,计算资源的调度器通常完全不知道 GPU 之间的通信线路和拓扑结构的信息。因此,被调度器分配给同一个任务的多个 GPU,很有可能其间的网络拓扑结构不规则,而且一个任务的多个 GPU 可能会被分配到不同机器上。
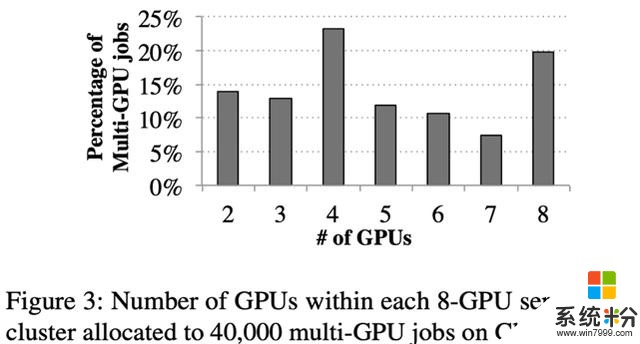
如图 3 所示,我们分析了一个微软内部机群的任务调度日志。其所用的机器大多数是 8 卡的 DGX-1。我们发现,虽然用户基本都在申请使用 2 的幂的数量的 GPU,但在每一台 DGX-1 机器上,分给同一个用户任务的 GPU 数量会存在 3,5,6,7 这种数量。
如上三点的网络异构性,导致很多 GPU 间的通信线路没有被充分利用。例如图 2(b)所示(GPU 的 ID 对应图 1),当任务调度器在一台 DGX-1 机器上,分配给一个任务的 3 个 GPU 是 GPU0,1,4 时,由于 GPU1 和 GPU4 之间没有直接相连的 NVLink,由于无法建立环状通信通道,此时 NCCL/Horovod 会直接放弃 GPU0-GPU1 和 GPU0-GPU4 之间的两条高速通信线路 NVLink,转而完全使用低速的 PCIe 去做数据聚合。
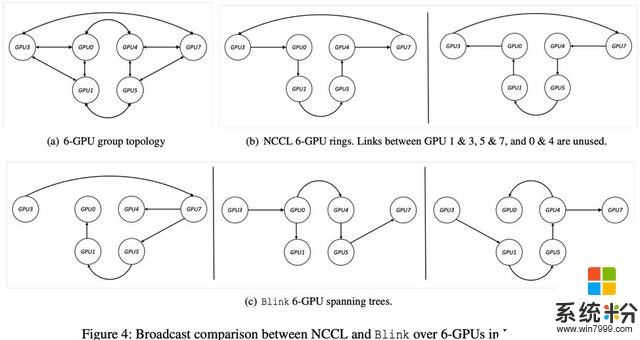
再者,即使分配给同一个任务的 GPU 间 NVLink 可以构成环状通信通道,由于环状通信通道本身的不灵活性(例如在一个环状通信通道中,任意 GPU 只能有一个输入接口和一个输出接口,而不能是多个输入或输出),导致 NCCL/Horovod 也无法利用所有的同构的高速线路 NVLink。如图 4 所示,在一个广播(Broadcast)的应用场景下,6GPU 的网络拓扑结构如图 4(a)所示,NCCL/Horovod 在这种情况下,可以构建两个单向的环状通道(图 4(b)所示),这种做法使得 GPU1&3,GPU5&7,GPU0&4 之间的高速 NVLink 完全未被使用。
为了解决如上问题,我们提出 Blink,一个最优的 GPU 间数据聚合的通信库。
首先,为了解决拓扑结构的不规则性,在同构网络中,Blink 可以自动生成最优的多个数据聚合通道。为了充分利用所有现有的 GPU 间数据通信线路,Blink 放弃了搭建环状(Ring)的数据聚合通道,使用一种更灵活高效的生成树(spanning tree)协议。相比于环,生成树可以更好的适应任意网络拓扑结构,使其更高效的利用所有通信线路。如图 2(b)所示,Blink 可以使用不能构成环的两条 NVLink 用来做 GPU 间数据拟合。如图 4(c)所示,生成树在同样的同构网络拓扑结构下,可以同时建立 3 个可并行的数据聚合通道,相比于 NCCL/Horovod 的 2 个环状通道。我们把每个 GPU 上需要数据聚合的数据总量叫做 N,同构线路的带宽叫做 B,则在这个环境下,Blink 的通信时间可以由 NCCL/Horovod 的 N/2B 缩减为 N/3B。
其次,根据不同带宽的异构线路,我们可以根据其带宽,分配和平衡在其上做数据聚合的数据量大小,从而实现多个异构通道并行完成数据聚合。如图 2(b)所示,Blink 可以同时用 PCIe 和 NVLink 实现数据的并行传输。
最后,Blink 提供了和 NCCL 完全一致的函数接口(API),所以不需要修改任何用户层面的代码,Blink 就可以无缝使用到当下流行的分布式机器学习平台,例如 PyTorch,TensorFlow 等。
实验结果
1. Broadcast, AllReduce 基准测试
我们在三个多 GPU 的平台进行了 Broadcast 和 AllReduce 的数据聚合测试。三个平台分别为由 P100 GPU 组成的八卡机器 DGX-1-P00,由 V100 GPU 组成的 DGX-1-V100 和 DGX-2。基准测试的横轴的数字序列均代表所使用的 GPU 的 ID,可以直接映射到图 1。这些 GPU 的序列代表当下机器上所有可能出现的不同的拓扑结构。实验的比较对象是 2019 年 7 月最新发布的 NCCL v2.4。
实验结果如下:
1.1 基于 DGX-1-V100 的 Broadcast,AllReduce 测试
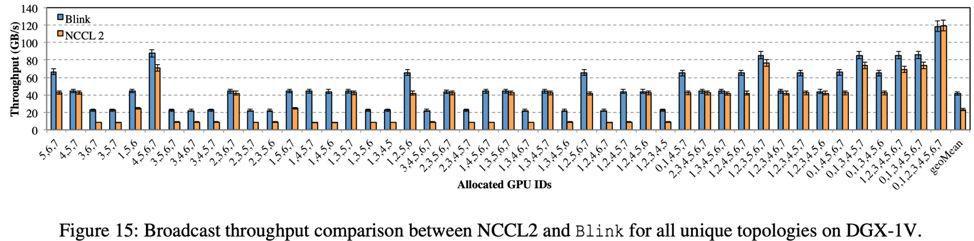
Broadcast 测试结果如图 15 所示,在 DGX-1-V100 上,Blink 可以提速数据聚合效率高达 6 倍(平均 2 倍)。
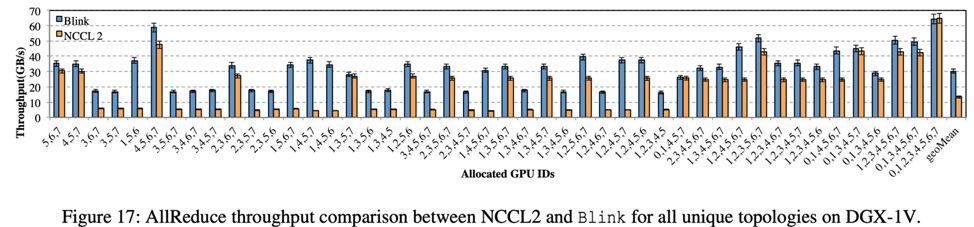
AllReduce 是 GPU 间数据聚合最频繁使用的方式。测试结果如图 17 所示,相比 NCCL,Blink 可提升数据聚合的吞吐率高达 8 倍(平均 2 倍)
1.2 基于 DGX-1-P00 的 Broadcast 测试
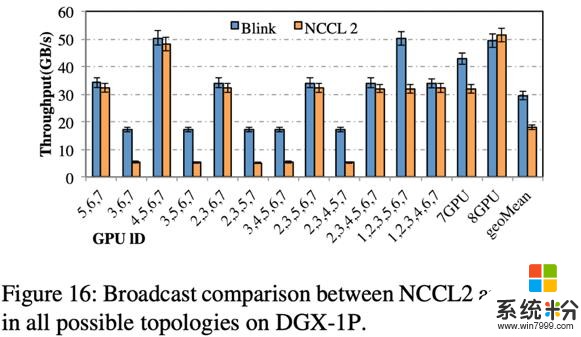
如图 16 所示,相比 DGX-1-V100,DGX-1-P100 的不同拓扑结构数量少,原因在于其 NVLink 网络的拓扑结构是更为规则的 hyper-cube(图一黑线所示)。相比 NCCL,Blink 可以提升通信效率高达 3 倍(平均提高 1.6 倍)。
1.3 基于 DGX-2 的 AllReduce 测试
DGX-2 是集成了 16 个 GPU 的大型计算机器。相比与 DGX-1,DGX-2 里面新加入了多个 NVSwitch 芯片,可以更好的实现 GPU 间点对点的无冲突通信。
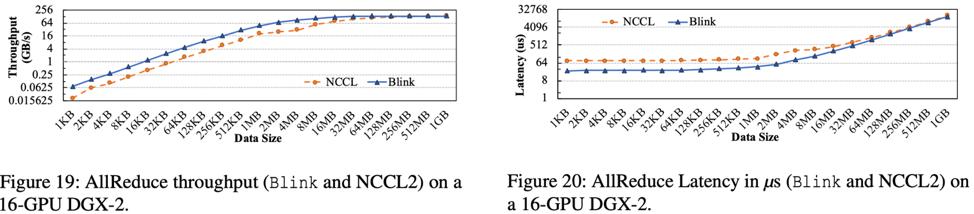
实验结果如图 19 和 20 所示,Blink 可以提升 AllReduce 吞吐率高达 3.5 倍,减小通信延迟高达 3.32 倍。
2. 异构线路吞吐率测试
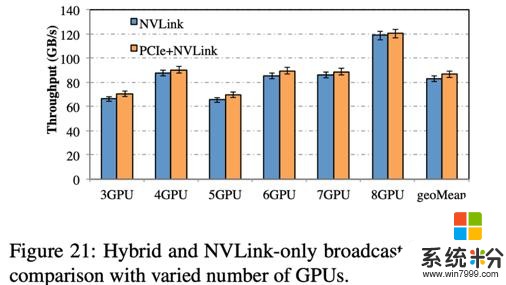
我们测试了在 DGX-1-V100 上的 PCIe 和 NVLink 通过 Blink 实现异构通信。结果如图 21 所示,相比于只利用 NVLink,加上 PCIe 实现异构通道并行数据聚合,可以提高整体通信吞吐率 2-5GB/s。
3. 机器学习模型训练测试
我们使用图像分类作为我们的实验任务。我们在 ImageNet-1K 数据集上,分别对四种不同的 CNN(AlexNet, ResNet18, ResNet50, VGG16)进行了分布式模型训练。单机和多机测试均用的 DGX-1-V100。
3.1 单机测试

单机测试结果如图 18 所示,相比 NCCL,Blink 可以最多减少 87% 的 GPU 数据聚合时间(平均减少 31%),从而导致 Blink 可以缩短整个模型训练时间高达 40%(平均 6.3%)。
3.2 多机测试
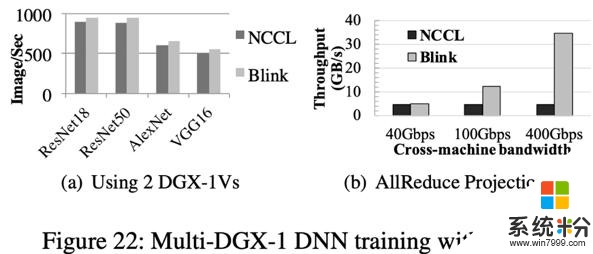
多机测试结果如图 22(a)所示,相比 NCCL,Blink 在分布式 CNN 模型训练中,图片的吞吐率(Image/Sec)提高 11%。提升不显著的根本原因是因为机器间的通信线路仍采用 40Gbps 的低速以太网,使其成为了数据聚合的瓶颈。我们根据当下可以达到的机器间通信带宽做了仿真测试,如图 22(b)所示,相比 NCCL,Blink 最多可以提升数据聚合吞吐率高达 7 倍。










