微软:用你的笑来奖励AI,它会做的更好
时间:2019-12-30 来源:互联网 浏览量:
受此启发,Microsoft研究人员开发了一个框架—— imbuing reinforcement learning,该框架包括一种通过愉悦之类的动机来激励主体的机制。
该框架包括:
可学习概括策略的连续的决策框架。
积极的内在情感模型,用于改变行为选择,使其偏向于提供更好的内在回报的行为。
使用在代理探索过程中收集的数据来构建视觉识别和理解任务的表示的组件。
该框架是一种人工智能训练技术,它利用奖励来激励系统朝着目标前进,具有积极的影响。他们认为,这可能会对收集与学习相关的重要经验方面很有用。
正如研究人员所解释的那样,强化学习通常是通过在达到特定目标时提供政策特定的奖励来进行
有问题的是,外部奖励的范围很窄,难以定义,而内部奖励是独立于任务的,可以快速表明是成功还是失败。
为了追求一种内在的策略,研究人员开发了一个由人类情感所驱动的奖励系统——采用人类的微笑作为正面奖励。
用模拟奖励的计算机视觉系统以及使用数据解决多项任务的另一个系统,它将人类的笑容视为一种积极的情感。
该框架鼓励代理在不陷入危险的情况下可以探索虚拟或现实环境,其优点是对任何特定的机器智能应用程序均不可知。
积极的内在奖励可以预测人类在探索过程中的微笑反应,而顺序决策框架则可以学习通用政策。
至于积极的内在情感模型,它会改变动作选择,从而偏向于提供更好的内在奖励的动作,最后一个组件使用代理在探索期间收集的数据来构建视觉识别和理解任务的表示。

为了测试这个框架,研究人员收集了5名受试者的数据,这些受试者的任务是用车辆探索一个数字三维迷宫,并用同步镜头记录每个人脸上的表情。参与者仅被告知探索环境,受试过程中由开源算法计算和记录他们的微笑反应。
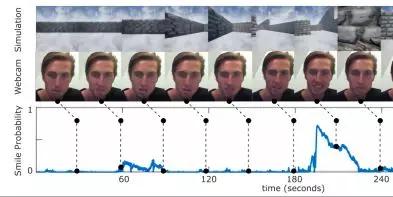
在一次驾驶过程中,微笑反应持续了6分钟(360秒)。从环境和网络摄像头视频帧显示作为参考。
基于情感的内在动机模型是使用受试者的数据进行训练的,其中来自车辆仪表板的图像帧作为输入,而微笑概率作为输出。
实验结果表明,使用笑容作奖励机制的学习过程可以带来更好的效果。与基线相比,研究人员的内在奖励政策在迷宫中的覆盖面积增加了46%,与障碍物的碰撞时间减少了29%。
研究人员表示,他们并不是尝试模仿人类的情感,而是要证明使用情感作为标记的训练,可以提升运算效果。
这种受情感机制引发内在奖励的学习框架,可以更有效提升覆盖度和减少失败次数,获得的经验可以有助解决不同应用例如深度估算、场景分割以及草图变图像等等。
原文链接:
https://venturebeat.com/2019/12/27/microsoft-proposes-ai-that-improves-when-you-smile/
视频点击预测大赛火热进行中
3万元奖金、证书、实习、就业机会已准备就位,快叫上小伙伴一起来组队参赛吧。
赛题:希望参赛者通过已有的用户信息、视频信息以及他们是否观看过某些视频,来预测我们推荐给这些用户的视频对方是否会观看。
个人、高等院校、科研单位、互联网企业、创业团队、学生社团等人员均可报名。
报名及组队时间:即日起至2020年2月1日
报名入口:
http://www.turingtopia.com/competitionnew/detail/e4880352b6ef4f9f8f28e8f98498dbc4/sketch
相关资讯
最新热门游戏
微软资讯推荐
- 1 微软重新定义的学生本值得买吗?文化的差异是个问题
- 2 微软首席执行官:隐私是一项需要被保护的人权
- 3 华为余承东:Win10系统已经OK了,现在可以继续欢呼
- 4Windows 10最新预览版“任务管理器”增加GPU性能追踪
- 5免费升级win10倒计时还有4天,现在不升级将来要多花800块
- 6微软又开始抛弃用户: 仅11款WP手机支持创意者更新(开放和封闭, 微软对于这个问题有自己的理解)
- 7Wintel联盟要掰? 微软展示首款Win 10-ARM笔记本
- 8电脑要卖不出去?戴尔、微软、惠普都急了
- 9微软将在10月份停止对Win10 1511的支持
- 10最强游戏机来了! 微软Xbox One X国行过审 期待不?
