Win10环境下的Scrapy结合Tor进行匿名爬取
时间:2017-05-27 来源:互联网 浏览量:

原文:http://www.cnblogs.com/kylinlin/p/5242266.html
在使用Scrapy的时候,一旦进行高频率的爬取就容易被封IP,此时可以通过使用TOR来进行匿名爬取,同时要安装Polipo代理服务器。
注意:要进行下面的操作的前提是,你能FQ
安装TOR
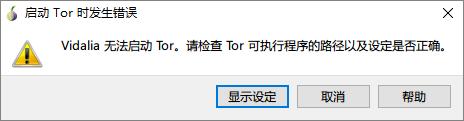
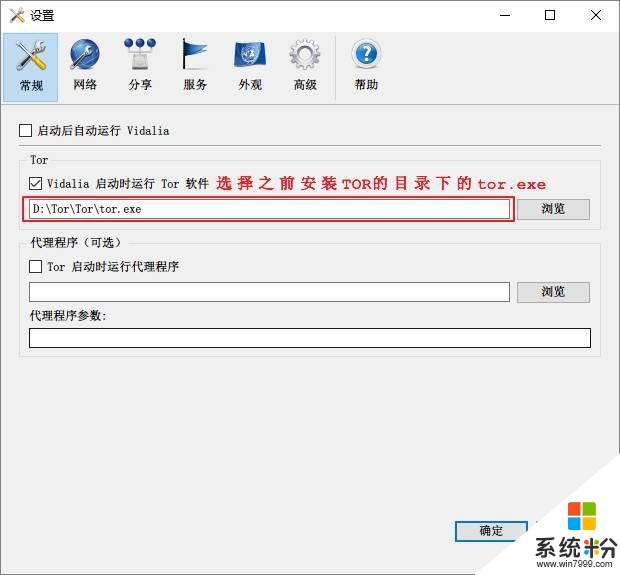
点击启动Tor
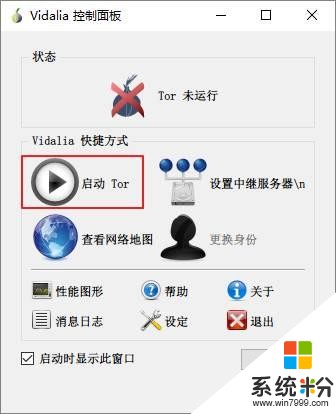
过一阵子后显示连接成功
 下载安装Polipo
下载安装Polipo选择polipo-1.1.0-win32.zip,下载并解压,然后编辑解压后的文件config.sample,在文件的开头加上以下配置
socksParentProxy = "localhost:9050"
socksProxyType = socks5
diskCacheRoot = ""
使用cmd命令运行该目录下的程序:polipo.exe -c config.sample

打开edge浏览器,设置代理
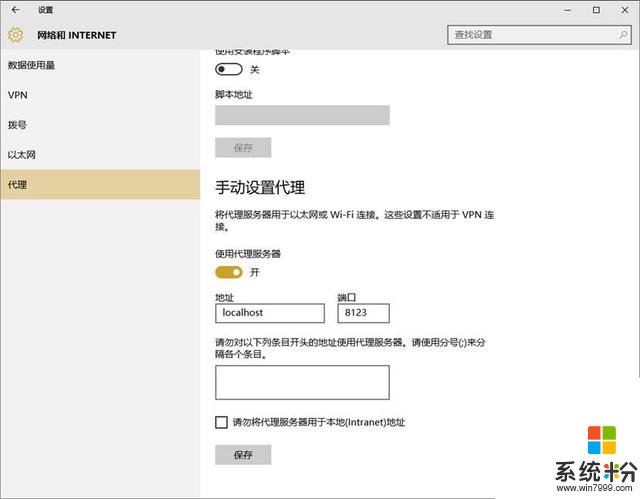
然后在浏览器中访问:
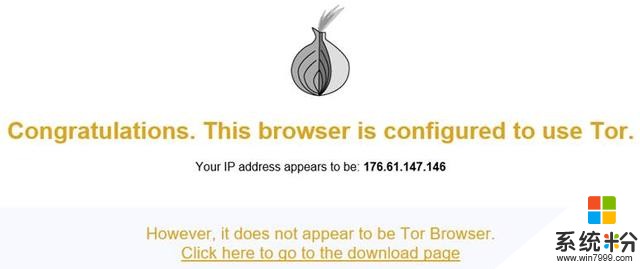
看到以下的界面意味着配置成功
 配置Scrapy
配置Scrapy在settings.py文件中加入下面的内容
#More comprehensive list can be found at
#http://techpatterns.com/forums/about304.html
USER_AGENT_LIST = [
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.7 (KHTML, like Gecko) Chrome/16.0.912.36 Safari/535.7',
'Mozilla/5.0 (Windows NT 6.2; Win64; x64; rv:16.0) Gecko/16.0 Firefox/16.0',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_3) AppleWebKit/534.55.3 (KHTML, like Gecko) Version/5.1.3 Safari/534.53.10',
]
HTTP_PROXY = 'http://127.0.0.1:8123'
DOWNLOADER_MIDDLEWARES = {
'myspider.middlewares.RandomUserAgentMiddleware': 400, # 修改这里的myspider为项目名称
'myspider.middlewares.ProxyMiddleware': 410, # 同上
'scrapy.contrib.downloadermiddleware.useragent.UserAgentMiddleware': ,
}
在scrapy项目的根目录新建一个middlewares.py文件,并输入以下内容
import random
from scrapy.conf import settings
from scrapy import log
class RandomUserAgentMiddleware(object):
def process_request(self, request, spider):
ua = random.choice(settings.get('USER_AGENT_LIST'))
if ua:
request.headers.setdefault('User-Agent', ua)
#this is just to check which user agent is being used for request
spider.log(
u'User-Agent: {} {}'.format(request.headers.get('User-Agent'), request),
level=log.DEBUG
)
class ProxyMiddleware(object):
def process_request(self, request, spider):
request.meta['proxy'] = settings.get('HTTP_PROXY')
至此,scrapy与tro的整合完成了,本文不对任何人使用这个方法所造成的后果负责
配置Tor浏览器下面的内容与上面无关,只是记录一下如何使用Tor浏览器,在我们下载tor的页面上,还有一个下载选项(第一个就是一个浏览器,通过该浏览器可以匿名访问网页,Tor Browser会自动通过Tor网络启动Tor的后台进程连接网络。一旦关闭程序的便会自动删除隐私敏感数据,如HTTP cookie和浏览历史记录,以避免窃听并保留在互联网上的隐私)
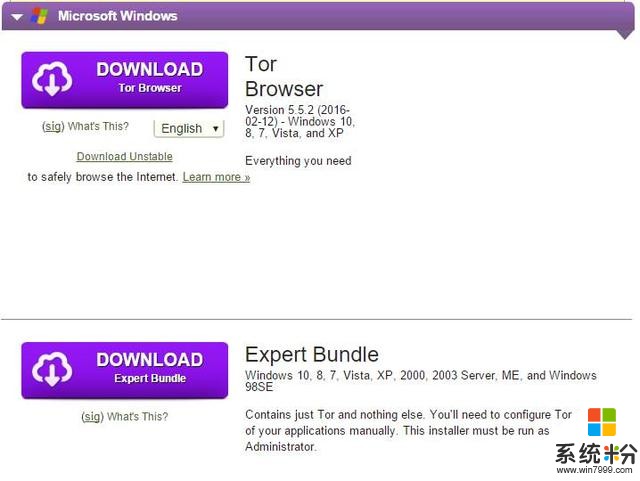
下载了第一个Tor Browser并安装后,进行下面的配置
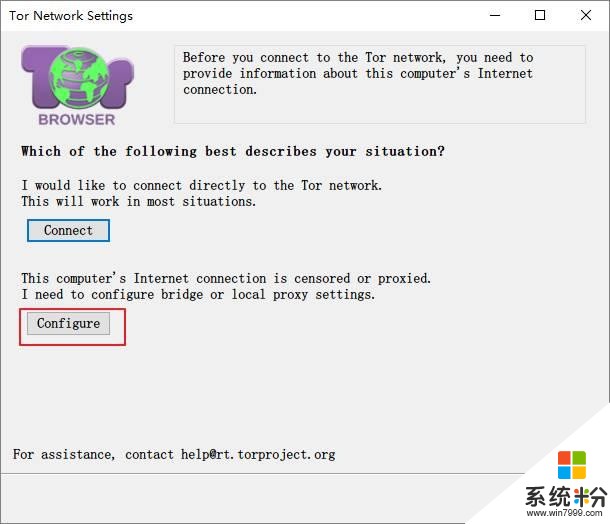
由于Tor的连接被墙掉了,所以要配置网桥
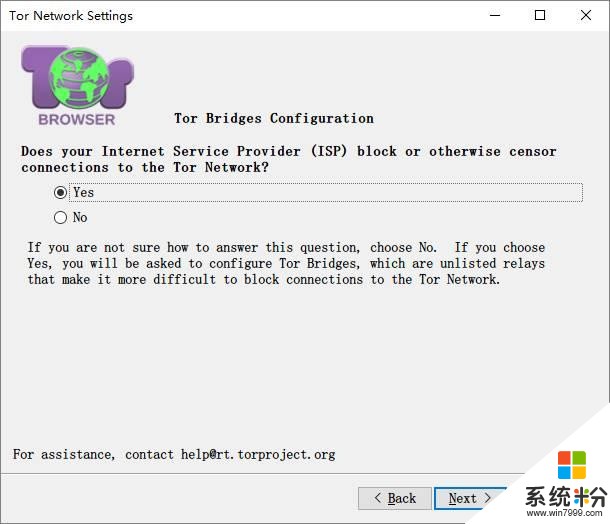
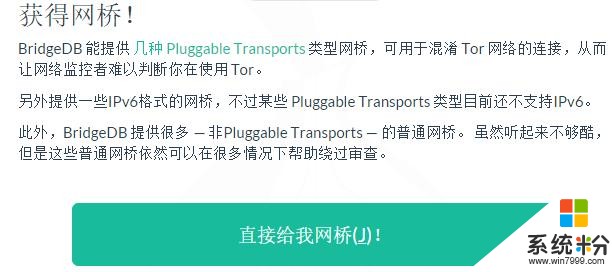
获取网桥:
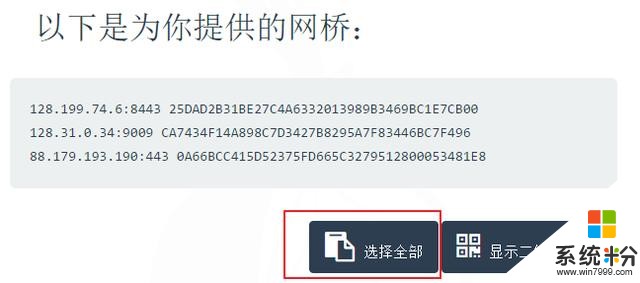
将网桥复制下来,粘贴到tor浏览器上
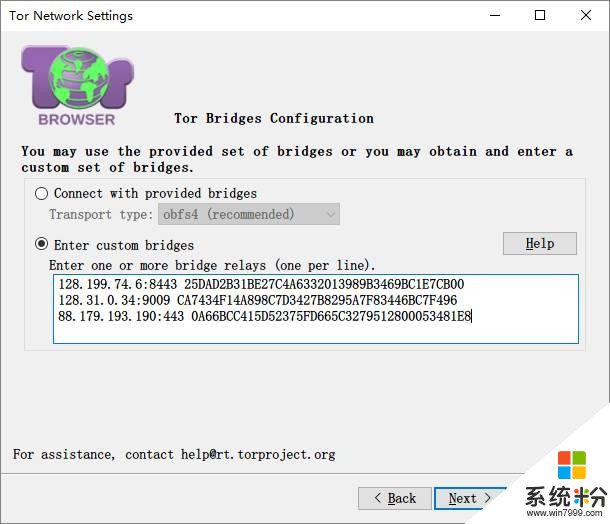
有时候连接不成功,就要再申请新的网桥来尝试
题图:pexels,CC0 授权。
相关资讯
最新热门游戏
微软资讯推荐
- 1 微软重新定义的学生本值得买吗?文化的差异是个问题
- 2 微软首席执行官:隐私是一项需要被保护的人权
- 3 华为余承东:Win10系统已经OK了,现在可以继续欢呼
- 4Windows 10最新预览版“任务管理器”增加GPU性能追踪
- 5免费升级win10倒计时还有4天,现在不升级将来要多花800块
- 6微软又开始抛弃用户: 仅11款WP手机支持创意者更新(开放和封闭, 微软对于这个问题有自己的理解)
- 7Wintel联盟要掰? 微软展示首款Win 10-ARM笔记本
- 8电脑要卖不出去?戴尔、微软、惠普都急了
- 9微软将在10月份停止对Win10 1511的支持
- 10最强游戏机来了! 微软Xbox One X国行过审 期待不?
